Base64,该你上场了

今天是农历正月十五,一般十五过完也代表农历春节过完,心思应该回归正常的工作中。节前因为“秋后算账”式的绩效搞的本来想写的延更到现在才写。在这个过程中也让我明白了一些事情,借用”左耳朵耗子“的名言:
一个人真正的绩效,应该是不依赖于某个公司的资源,不依赖于他人的帮助,而完全靠自己的能力,自己的聪明才智,整合并利用身边并不属于自己的资源,而能达到的常人不能达到的成绩。
- 一个人真正的绩效是自己的领导力。就是那种别人有问题会来请你帮助,而你总是能解决的能力。
- 一个人真正的绩效是别人尊重你,信任你,并愿意跟随你的现像。
盗刷又来
突然收到CDN域名的流量报警和违规图片预警,通过分析带宽波峰日志确定了上传的渠道,再通过ELK确定来自于哪个系统的上传。分析上传的图片,发现还是之前遇到的视频伪装图片,具体如下图所示:


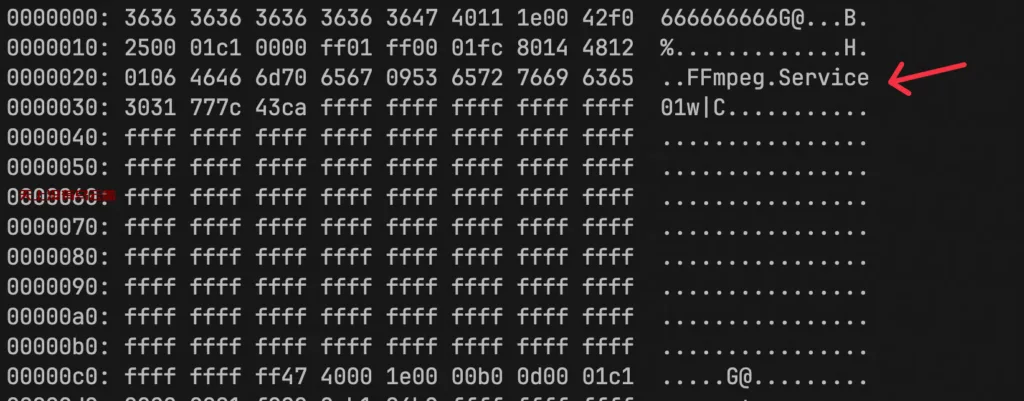
这种上传真挺无聊的,可能因为我们上传这边的漏洞太多被黑产盯上了,无时无刻不在找我们系统的漏洞。还真让他们找到了一个反馈系统的漏洞,反馈系统本意是让用户上传一些APP使用的反馈图片,方便解决用户问题,在上传这块没有做严格的限制,用户上传后能看到上传图片完整的CDN资源地址,这个漏洞被黑产利用上传视频伪装图片进行了流量盗刷。
处理过程
把漏洞反馈给业务开发同学,一起商讨确认前端展示用户上传返回的图片使用Base64编码,不直接返回CDN资源地址,这样可以有效封堵这个漏洞,修复逻辑如下图:

Base64原理
Base64是最常见的用于传输8Bit字节码的编码方式之一,它是一种基于64个可打印字符来表示二进制数据的方法。Base64编码,是由64个字符组成编码集:26个大写字母A~Z,26个小写字母a~z,10个数字0~9,符号“+”与符号“/”。Base64编码的基本思路是将原始数据的三个字节拆分转化为四个字节,然后根据Base64的对应表,得到对应的编码数据。当原始数据凑不够三个字节时,编码结果中会使用额外的符号“=”来表示这种情况。
创建一个动画来演示一下(基于阿里通义千问-Max模型来完成的实现)
#coding:utf-8
import base64
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from PIL import Image
import io
class Base64Animator:
def __init__(self, text):
if not isinstance(text, str) or not text.strip():
raise ValueError("输入文本不能为空或仅包含空白字符")
self.text = text
self.bytes = text.encode('utf-8')
self.steps = self._create_steps()
self.fig, self.ax = plt.subplots(figsize=(8, 6)) # 固定画布大小为 800x600
self.current_step = 0
self.colors = plt.cm.tab10.colors
# 统一设置中文字体
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
def _create_steps(self):
steps = []
steps.append(("原始文本", self.text, []))
steps.append(("转换为字节", f"字节序列: {list(self.bytes)}", []))
binary = ''.join(f"{byte:08b}" for byte in self.bytes)
steps.append(("二进制表示", binary, []))
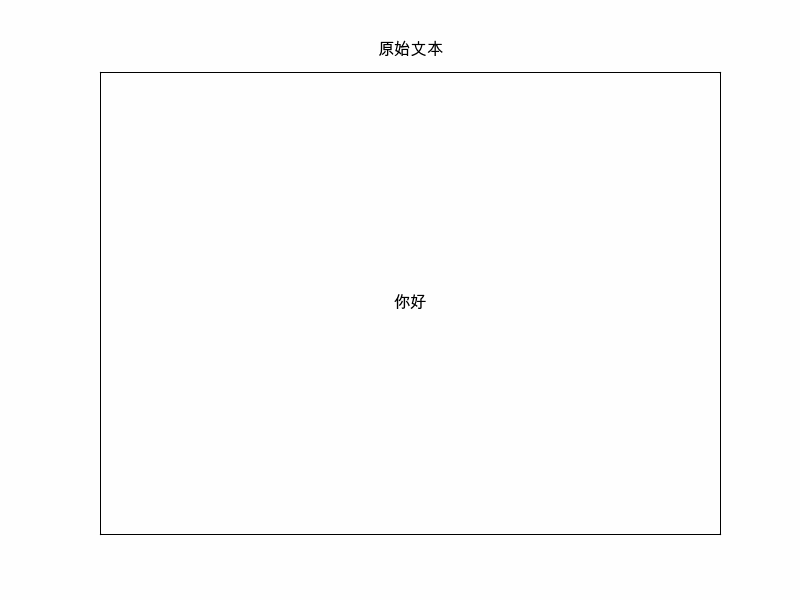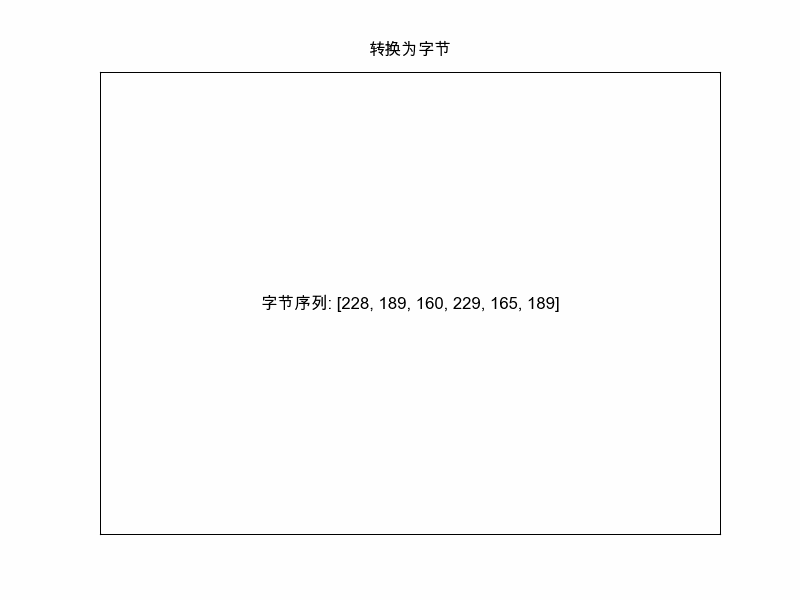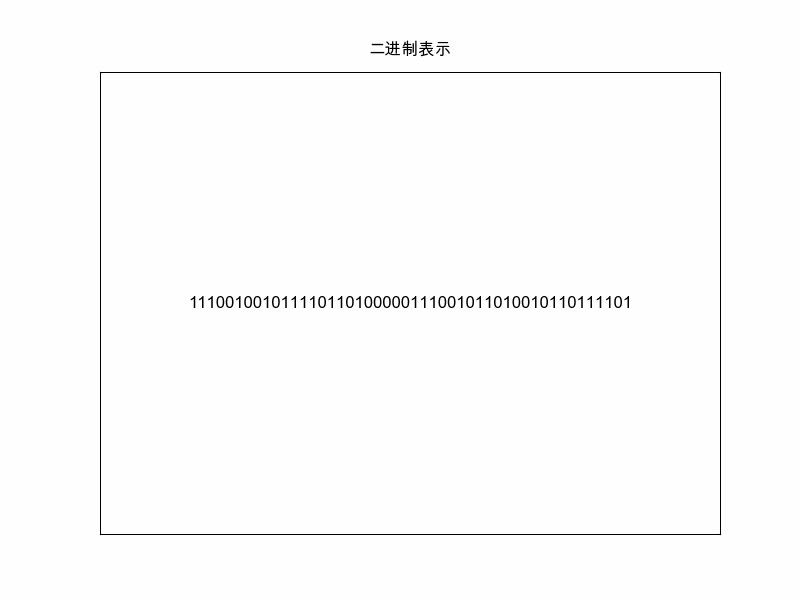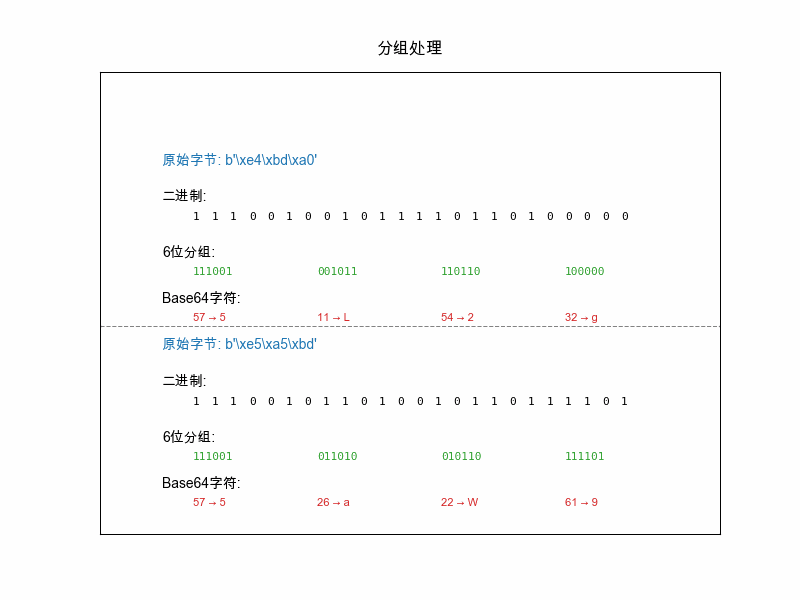
chunks = []
for i in range(0, len(self.bytes), 3):
chunk = self.bytes[i:i+3]
bin_str = ''.join(f"{b:08b}" for b in chunk)
padding = (3 - len(chunk)) * 8
bin_str += '0' * padding
groups = [bin_str[j:j+6] for j in range(0, 24, 6)][:4]
indices = [int(g, 2) for g in groups]
chars = [self._b64_char(i) for i in indices]
if padding == 8:
chars[-1:] = ['=']
chars[-2:] = ['=', '=']
elif padding == 16:
chars[-1:] = ['=']
chunks.append((chunk, bin_str, groups, indices, chars))
steps.append(("分组处理", chunks, []))
return steps
def _b64_char(self, index):
chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
return chars[index]
def _draw_text(self, step_info):
self.ax.clear()
# 设置标题并调整其位置
self.ax.set_title(step_info[0], fontsize=12, fontweight='bold', y=1.02) # 减小字体大小并微调位置
self.ax.set_xticks([])
self.ax.set_yticks([])
if step_info[0] == "分组处理":
self._draw_group_processing(step_info[1])
else:
plt.text(0.5, 0.5, step_info[1],
ha='center', va='center',
fontsize=12, # 固定字体大小
fontfamily='Arial Unicode MS')
def _draw_group_processing(self, chunks):
y = 0.8 # 初始位置稍微降低一些
for i, chunk in enumerate(chunks):
# 添加分隔线(横线)
if i > 0: # 从第二组开始添加横线
self.ax.axhline(y + 0.05, color='gray', linestyle='--', linewidth=0.8)
self.ax.text(0.1, y, f"原始字节: {chunk[0]}",
fontsize=10, color=self.colors[0],
fontfamily='Arial Unicode MS')
bin_str = chunk[1]
self.ax.text(0.1, y-0.08, "二进制:",
fontsize=10, fontfamily='Arial Unicode MS')
for j, bit in enumerate(bin_str):
color = 'red' if (len(chunk[0])*8 < j+1) else 'black'
plt.text(0.15 + j*0.03, y-0.12, bit,
color=color, fontfamily='monospace', fontsize=8)
groups = chunk[2]
self.ax.text(0.1, y-0.2, "6位分组:",
fontsize=10, fontfamily='Arial Unicode MS')
for k, group in enumerate(groups):
plt.text(0.15 + k*0.2, y-0.24, group,
fontfamily='monospace', color=self.colors[2], fontsize=8)
self.ax.text(0.1, y-0.3, "Base64字符:",
fontsize=10, fontfamily='Arial Unicode MS')
for m, (index, char) in enumerate(zip(chunk[3], chunk[4])):
plt.text(0.15 + m*0.2, y-0.34, f"{index} → {char}",
color=self.colors[3],
fontfamily='Arial Unicode MS', fontsize=8)
y -= 0.4 # 每组之间留更小的间距
def update(self, frame):
self.current_step = frame
self._draw_text(self.steps[frame])
def animate(self):
interval = max(2000 // len(self.text), 500) # 动态调整间隔时间
ani = FuncAnimation(self.fig, self.update, frames=len(self.steps),
interval=interval, repeat=False)
# 手动调整子图边距,确保标题不会被裁剪
plt.subplots_adjust(top=0.8, bottom=0.1, left=0.1, right=0.9) # 增加顶部边距
plt.show()
plt.close('all') # 确保资源释放
def save_as_gif(self, filename='base64_animation.gif'):
frames = []
for frame in range(len(self.steps)):
self.update(frame)
buf = io.BytesIO()
self.fig.savefig(buf, format='png', dpi=100)
buf.seek(0)
frames.append(Image.open(buf))
# 保存为GIF
frames[0].save(filename, save_all=True, append_images=frames[1:], duration=1000, loop=0)
print(f"动画已保存为 '{filename}'")
# 使用中文测试
animator = Base64Animator("你好")
animator.save_as_gif()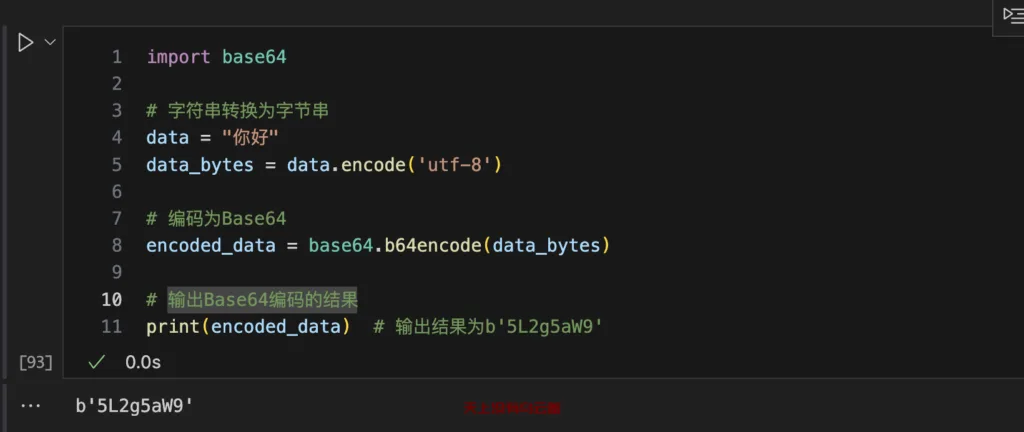
图片的话访问https://m.sukoutu.com/base64_img来进行转换

写在最后
经过与黑产团伙的长期动态攻防,我们通过持续迭代安全机制,在以下关键环节形成了多维度运维监控体系:1)流量预警后24小时处理结束;2)基于深度学习的异常图片智能识别模块;3)用户行为画像分析与展示防护机制。目前正深度整合DeepSeek大模型的智能推理能力,通过前沿AI技术对业务全链路进行风险预判,这将有效堵塞潜在安全漏洞,大幅提升系统对抗黑产恶意攻击的主动防御能力。
出现的历史背景
转载一篇写的非常好的文章,介绍Base64出现的背景非常详细。
作者:蓬岸 Dr.Quest
链接:https://www.zhihu.com/question/38036594/answer/2954195015
base64出现的目的,是为了让二进制流安全地通过为7-bit ASCII设计的电信网络

ASCII码是1960年代为电传打字网络设计的编码,使用7-bit表示一个字符,其中包含了大量用于控制通信设备的代码,比如EM(1001001)代表着end-of-media,媒体结束,代表着打孔纸带打完了。EOT(0100000)代表着end-of-transmission传输结束,此时通信设备进入待机或者切断线路。
我们不难想象,当我们通过上述电信网络传输二进制文件时,很可能遇到混乱,因为1001001、0100000都是很常见的二进制序列。

特别是当我们希望在7-bit ASCII电信网络上传输8-bit字节流,比如IBM大型机和BITNET所使用的8-bit EBCDIC编码,由于电信网络依次传输每个二进制位,因此可能会由于无法对齐而带来更多的故障
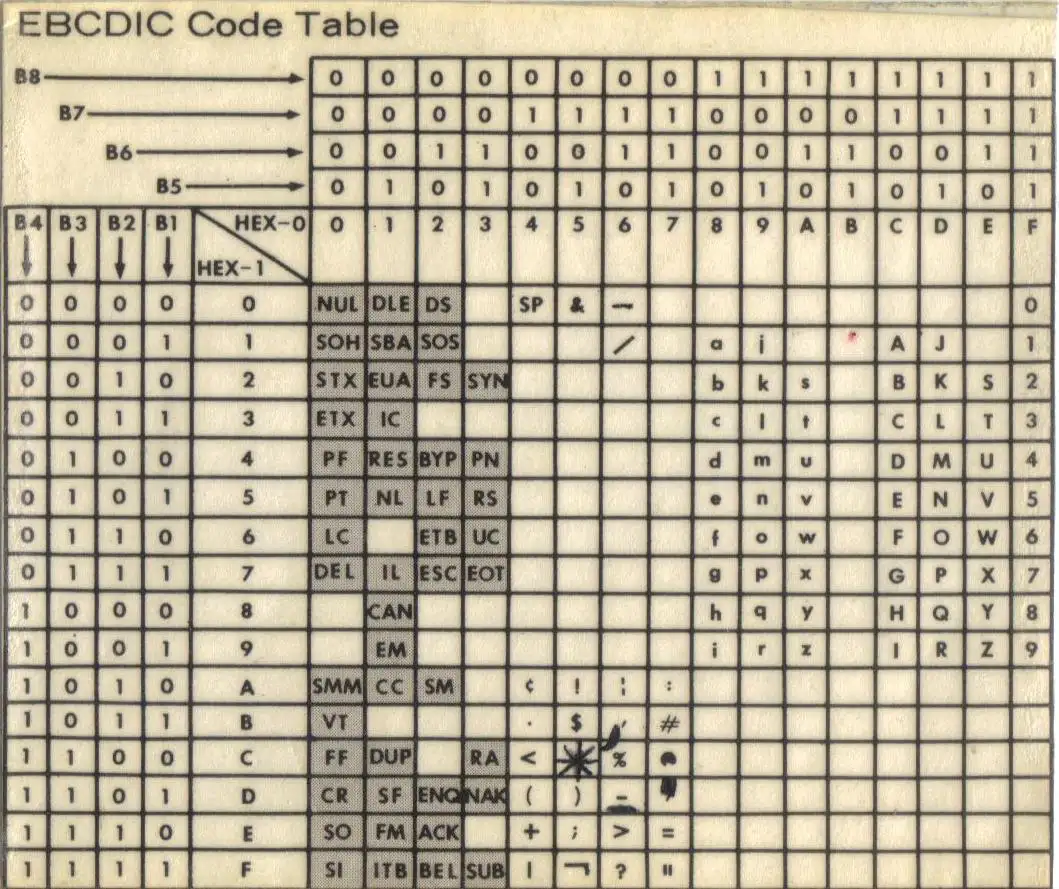
这时如果我们希望将EBCDIC的“hello”的二进制编码10001000 10000101 10010011 10010011 10010110
| 字符 | EBCDIC二进制 |
|---|---|
| h | 10001000 |
| e | 10000101 |
| l | 10010011 |
| l | 10010011 |
| o | 10010110 |
通过7-bit ASCII传输,就会被通信设备解释成1000100 0100001 0110010 0111001 0011100 10110
| 二进制 | ASCII 7-bit含义 |
|---|---|
| 1000100 | H |
| 0100001 | DC4,设备控制4,通常为暂停或关闭 |
| 0110010 | & |
| 0111001 | ETB,结束传输块 |
| 0011100 | C |
| 10110 | 未知(不完整的字符) |
因此这段二进制中有两个与“中止”或“结束”有关的控制字符,所以很可能传输就提前中断了。
而base64的作用,是让8-bit字节流以6-bit一组,编码为字符串安全地通过7-bit ASCII设备。
base64使用了大写字母A-Z,小写字母a-z,数字0-9,符号“+”和“/”这64个字母表示6-bit的数据。
| 二进制范围 | 十进制 | 字符 |
|---|---|---|
| 000000~011001 | 0~25 | A~Z |
| 011010~110011 | 26~51 | a~z |
| 110100~111101 | 52~61 | 0~9 |
| 111110, 111111 | 62~63 | + / |
然后上述EBDIC编码的“hello”就会被以6个bit一组被分成7组
| 6-bit二进制串 | Base64字符串 |
|---|---|
| 100010 | i |
| 001000 | l |
| 010110 | W |
| 010011 | T |
| 100100 | k |
| 111001 | 5 |
| 0110(以0填充最后两位为011000) | Y |
因为编码后的字符串不包含任何通信控制指令,它可以在7-bit ASCII电信网络上传输了,但我们会发现为了让最后四个二进制数0110能够编码,我们填了两个0,那么如何让接收者知道我们想传输的数据里实际不包含这两个0呢?
当年base64的设计者们也遇到了同样的问题,他们的解决方法是用base64字符串中每个字符的6-bit和8-bit字节流的最小公倍数24-bit作为一个编码块,这样每个编码块就包含4个字符或3个字节,而当字节数无法编码足够的字符时,就用等号“=”填充到四个字符。
| EBCDIC数据 | 24-bit编码块 | base64 |
|---|---|---|
| hel | 100010001000010110010011 | ilWT |
| lo | 1001001110010110(00)————– | k5Y= |
有一个等号说明该编码块中只能解码出两个8-bit字节(18-bit中的16-bit),多出的零则不解析,而有两个等号则说明该编码块中只能解码出一个8-bit字节(12-bit中的8-bit),比如我们要把8-bit EBCDIC编码的“code”,二进制10000011 10010110 10000100 10000101编码到base64,结果就是。
| EBCDIC数据 | 24-bit编码块 | base64 |
|---|---|---|
| cod | 100000111001011010000100 | g5aE |
| e | 10000101(0000)———— | hQ== |
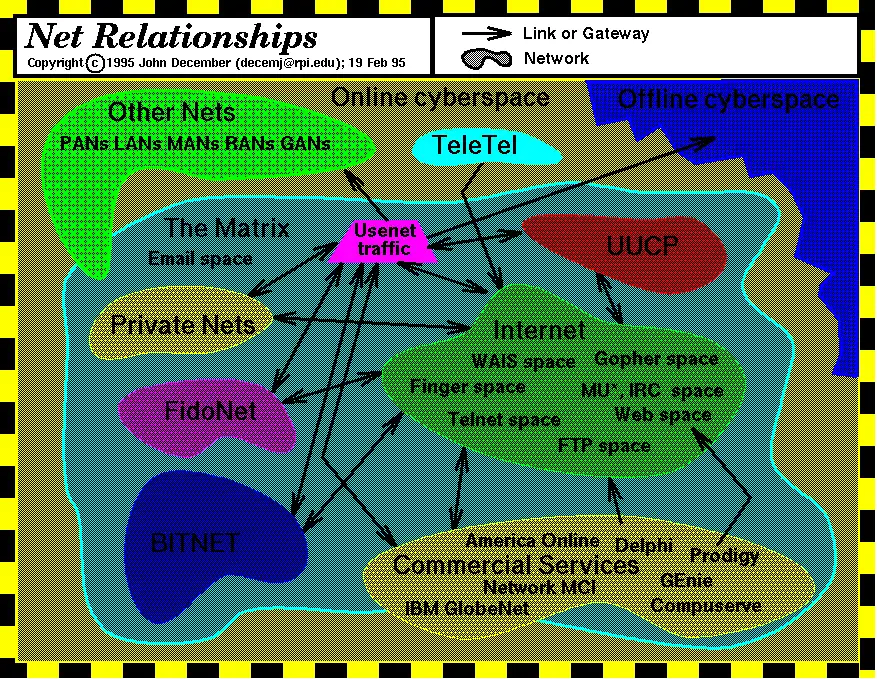
base64编码最重要的应用领域是电子邮件,打通了不同网络间电子邮件的互通问题。让使用7-bit ASCII的通信网络及其它可以互操作的计算机和通信系统,例如使用EBCDIC的BITNET间可以互换二进制文件。
可以电子邮件互通的Internet、UUCP、FidoNet(包括中国惠多网),BITNET、中国公众多媒体通信网网(即169网)和Compuserve、美国在线、国内的瀛海威时空等商业在线服务运营商构成了庞大的Email space,成为后来Internet整合诸多计算机网络的基础。