
wkhtmltopdf乱码

2024年从指尖轻轻滑走了,2025年又不期而遇。

事情起因
研发同学有一个内部系统需要支持打印发票的需求,使用wkhtmltopdf来把生成的html转成pdf方便打印。wkhtmltopdf的官网地址:https://wkhtmltopdf.org,
最新的版本是2020年的0.12.6,竟然5年都没有更新了。下载最新的wkhtmltox-0.12.6-1.centos7.x86_64.rpm来安装,有一些依赖包需要先装一下,如下:
dnf install xorg-x11-fonts-75dpi xorg-x11-fonts-Type1 libXrender libpng15安装过程没有遇到问题,系统中调用命令生成的html竟然是乱码。
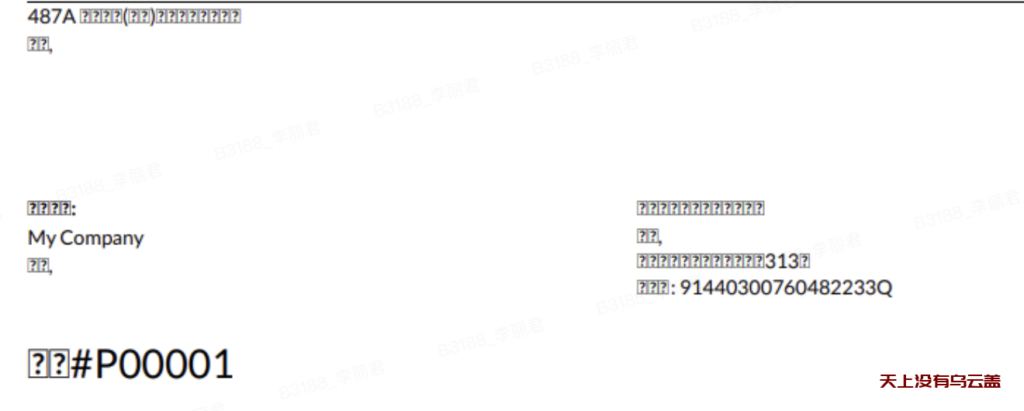
修复乱码
在网上搜索这个问题可以发现很多都是说是因为系统缺少中文字体文件导致的,比较代表性的:centos7命令行 安装中文输入法 centos7安装中文字体,按解决方案进行修复把字体拷贝进去,
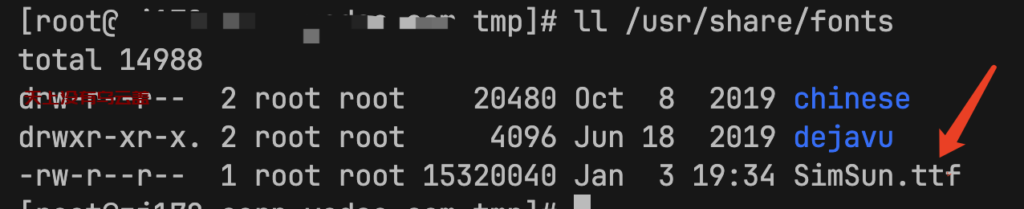

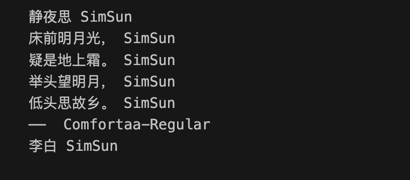
修改已生效,然后使用研发同学提供的一个测试test.html进行测试,html内容如下:
<!DOCTYPE html>
<html lang="zh-CN">
<body>
<div class="poem">
<h1>静夜思</h1>
<p>床前明月光,</p>
<p>疑是地上霜。</p>
<p>举头望明月,</p>
<p>低头思故乡。</p>
<p>—— 李白</p>
</div>
</body>
</html>运行转换命令,把html转成pdf,抓换过程中没有遇到报错。
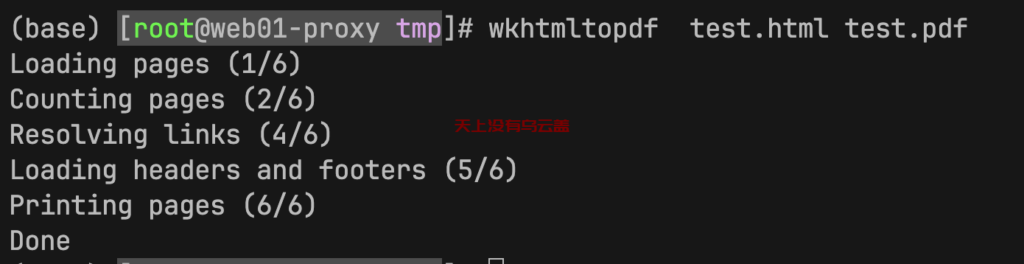
预览test.pdf发现是乱码
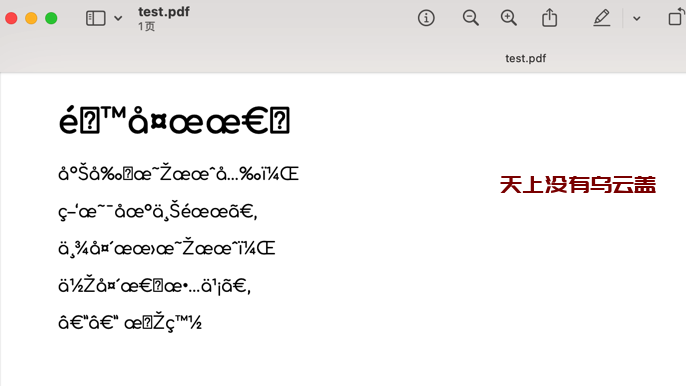
网上的解决方案基本上都是字体,鉴于已经解决了字体问题,怀疑是wkhtmltopdf使用的问题,查看具体的命令帮助https://wkhtmltopdf.org/usage/wkhtmltopdf.txt,有–encoding参数可以选择,网上这篇文章也有说到wkhtmltopdf 转换HTML为PDF时不显示中文
--encoding <encoding> Set the default text encoding, for input手动指定一下–encoding为utf-8,生成的pdf乱码问题解决了。

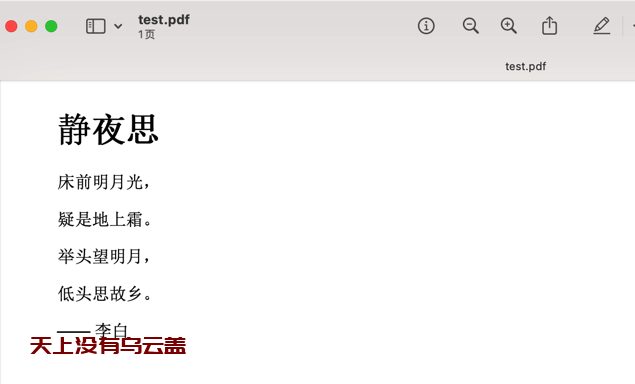
延伸扩展
搜到一篇[问题]wkhtmltopdf转换网页中文乱码问题解决方案 中提到网页编码问题,把test.html重命名成pdf.html并用Python启动一个简单的web服务,获取常见的网站和这个pdf.html的网页编码,发现也是utf-8
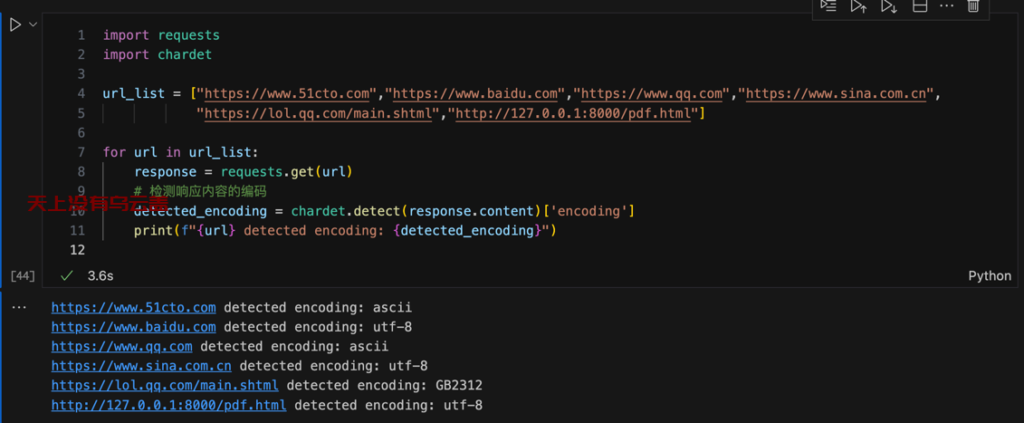
其他几个网站,百度访问特别慢,放弃掉,其他的几个有打开空白的(www.51cto.com),sina.com.cn是可以转成pdf的(网页编码是utf-8)
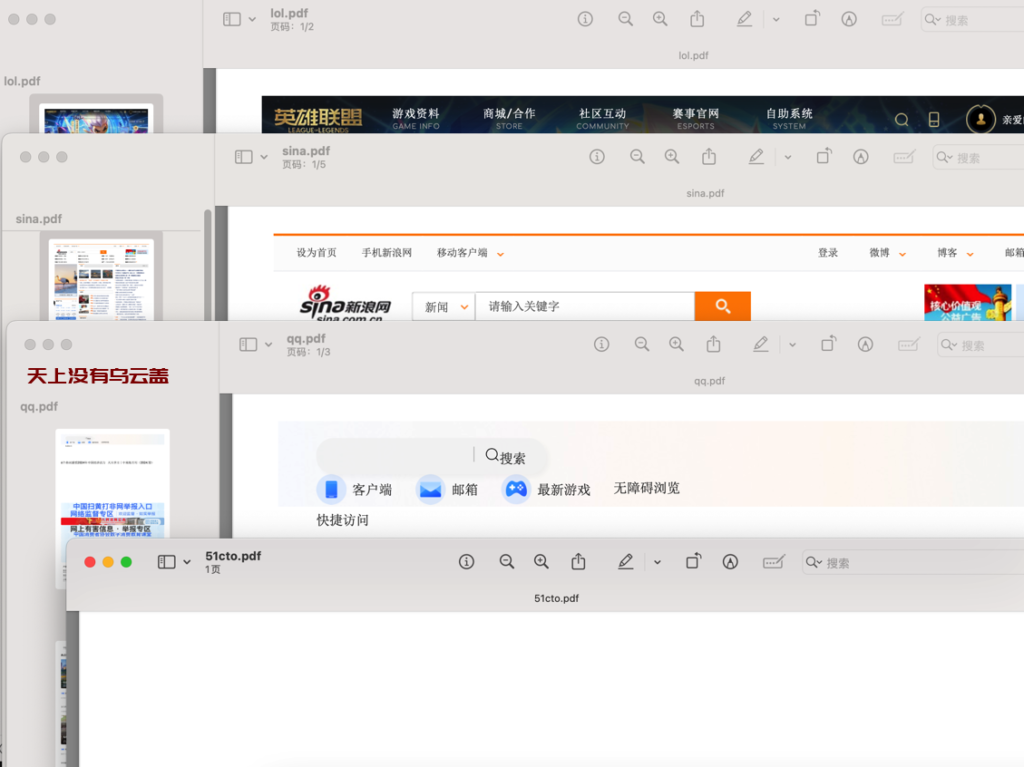
看一下转换完的pdf的文本的字符编码,包括正常的和乱码的
import fitz # PyMuPDF
# 打开PDF文件
pdf_file = "/Users/lilj/Downloads/qq.pdf"
doc = fitz.open(pdf_file)
# 遍历每一页
for page_num in range(len(doc)):
page = doc[page_num]
# 获取文本块(这里不考虑图像或其他类型的内容)
for block in page.get_text("dict")["blocks"]:
if 'lines' in block.keys():
for line in block["lines"]:
for span in line["spans"]:
print(span["text"], span.get("font", "unknown"))
else:
print("No text found on page", page_num)
# 关闭PDF文档
doc.close()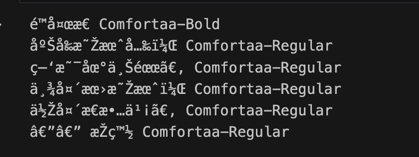
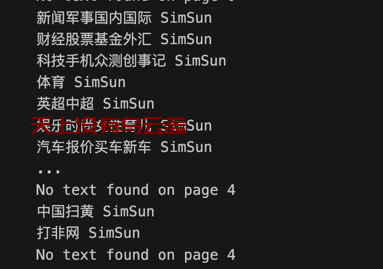
修改pdf.html,增加meta项设置html使用的字符集
<meta http-equiv="content-type" content="text/html;charset=utf-8">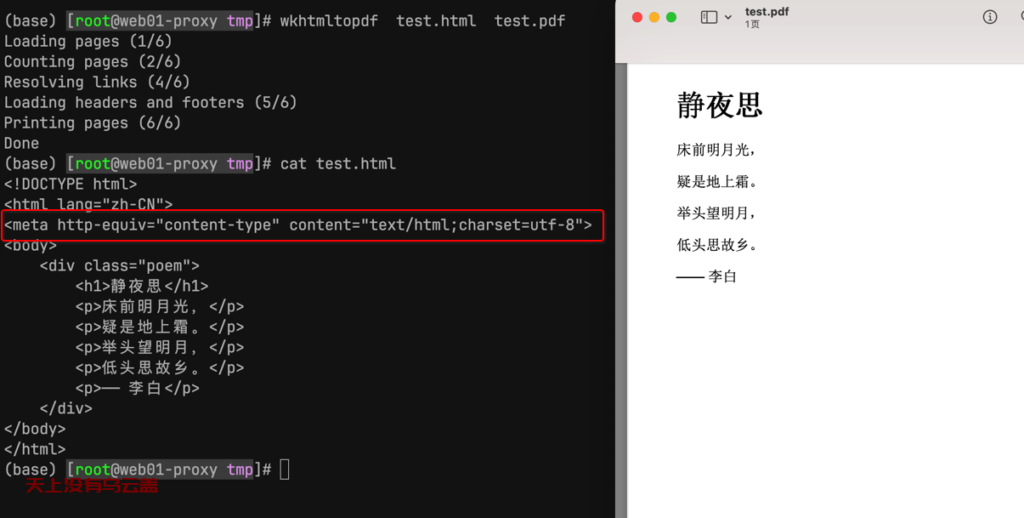
【META http-equiv=”Content-Type” Content=”text/html; Charset=*】意义详解
META,网页Html语言里Head区重要标签之一
HTTP-EQUIV类似于HTTP的头部协议,它回应给浏览器一些有用的信息,以帮助正确和精确地显示网页内容。常用的HTTP- EQUIV类型有:
Content-Type和Content-Language (显示字符集的设定)
说明:设定页面使用的字符集,用以说明主页制作所使用的文字已经语言,浏览器会根据此来调用相应的符集显示page内容。
<Meta http-equiv=”Content-Type” Content=”text/html; Charset=gb2312″>该META标签定义了HTML页面所使用的字符集为GB2132,就是国标汉字码。如果将其中的“charset=GB2312”替换成“BIG5”,则该页面所用的字符集就是繁体中文Big5码。当你浏览一些国外的站点时,IE浏览器会提示你要正确显示该页面需要下载xx语支持。这个功能就是通过读取HTML页面META标签的Content-Type属性而得知需要使用哪种字符集显示该页面的。如果系统里没有装相应的字符集,则IE就提示下载。其他的语言也对应不同的charset,比如日文的字符集是“iso-2022-jp ”,韩文的是“ks_c_5601”。
Content-Type的Content还可以是:text/xml等文档类型Charset选项:ISO-8859-1(英文)、BIG5、UTF-8、SHIFT-Jis、Euc、Koi8-2、us-ascii, x-mac-roman, iso-8859-2, x-mac-ce, iso-2022-jp, x-sjis, x-euc-jp,euc-kr, iso-2022-kr, gb2312, gb_2312-80, x-euc-tw, x-cns11643-1,x-cns11643-2等字符集;Content-Language的Content还可以是:EN、FR等语言代码。
字符集与编码
各个国家和地区所制定的不同 ANSI 编码标准中,都只规定了各自语言所需的“字符”。比如:汉字标准(GB2312)中没有规定韩国语字符怎样存储。这些 ANSI 编码标准所规定的内容包含两层含义:
1. 使用哪些字符。也就是说哪些汉字,字母和符号会被收入标准中。所包含“字符”的集合就叫做“字符集”。
2. 规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“编码”。
各个国家和地区在制定编码标准的时候,“字符的集合”和“编码”一般都是同时制定的。因此,平常我们所说的“字符集”,比如:GB2312, GBK, JIS 等,除了有“字符的集合”这层含义外,同时也包含了“编码”的含义。
“UNICODE 字符集”包含了各种语言中使用到的所有“字符”。用来给 UNICODE 字符集编码的标准有很多种,比如:UTF-8, UTF-7, UTF-16, UnicodeLittle, UnicodeBig 等。
1、ISO-8859-1:
最简单的编码规则,每一个字节直接作为一个 UNICODE 字符。比如,[0xD6, 0xD0] 这两个字节,通过 iso-8859-1 转化为字符串时,将直接得到 [0x00D6, 0x00D0] 两个 UNICODE 字符,即 “ÖД。
反之,将 UNICODE 字符串通过 iso-8859-1 转化为字节串时,只能正常转化 0~255 范围的字符。
2、GB2312,BIG5,Shift_JIS,ISO-8859-2
把 UNICODE 字符串通过 ANSI 编码转化为“字节串”时,根据各自编码的规定,一个 UNICODE 字符可能转化成一个字节或多个字节。
反之,将字节串转化成字符串时,也可能多个字节转化成一个字符。比如,[0xD6, 0xD0] 这两个字节,通过 GB2312 转化为字符串时,将得到 [0x4E2D] 一个字符,即 ‘中’ 字。
“ANSI 编码”的特点:
1. 这些“ANSI 编码标准”都只能处理各自语言范围之内的 UNICODE 字符。
2. “UNICODE 字符”与“转换出来的字节”之间的关系是人为规定的。
3、UTF-8,UTF-16,UnicodeBig
与“ANSI 编码”类似的,把字符串通过 UNICODE 编码转化成“字节串”时,一个 UNICODE 字符可能转化成一个字节或多个字节。
与“ANSI 编码”不同的是:
1. 这些“UNICODE 编码”能够处理所有的 UNICODE 字符。
2. “UNICODE 字符”与“转换出来的字节”之间是可以通过计算得到的。
<Meta http-equiv=”Content-Type” Content=”text/html; Charset=gb2312″>该META标签定义了HTML页面所使用的字符集为GB2132,就是国标汉字码。
写在最后
wkhtmltopdf 添加–encoding不能保证每次html转换的pdf没有乱码,最好的办法还是在系统生成的html中添加 META charset 字符集设置,这样wkhtmltopdf 进行转换后的pdf不会再出现乱码。
2025年开个好头,一年顺利!~
