
windows下的ollama
ollama出来一段时间了,在mac上面跑模型的时候有时候比较卡,台式机上有独立的4060卡,想着换到上面速度能快一些,没有想到安装过程中比较曲折。
需要注意ollama调整绑定的地址和model地址都在环境变量里面配置,实例如下:
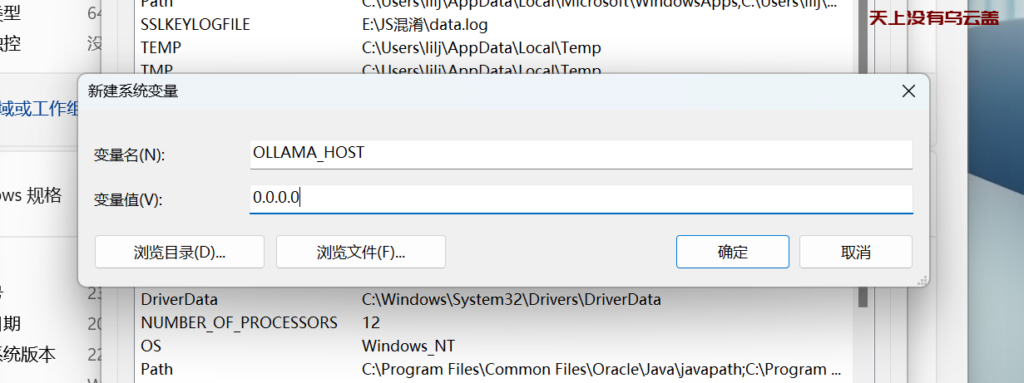
WSL
在ollama官网下载windows版本进行安装,在cmd终端中启动后可以输入,但是还是略显麻烦。正好有一个open-webui的开源项目,可以在浏览器中很方便调用ollama的服务。安装需要有容器环境,去下载dockerdesktop进行安装后竟然要登录,这网络也登录不上去啊。哎,幸好有替代的podman,去官网看安装竟然需要WSL环境,学习了。
WSL是适用于 Linux 的 Windows 子系统 (WSL) 是 Windows 的一项功能,可用于在 Windows 计算机上运行 Linux 环境,而无需单独的虚拟机或双引导。WSL 旨在为希望同时使用 Windows 和 Linux 的开发人员提供无缝高效的体验。
参考官方安装文档:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart第二步安装 https://learn.microsoft.com/en-us/windows/wsl/install-manual#step-3—enable-virtual-machine-feature
下载wsl_update_x64.msi进行安装
wsl --set-default-version 2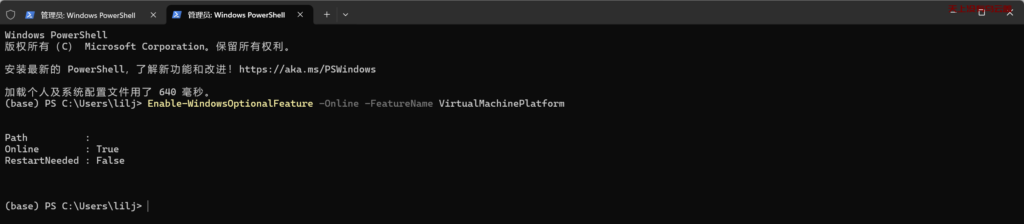
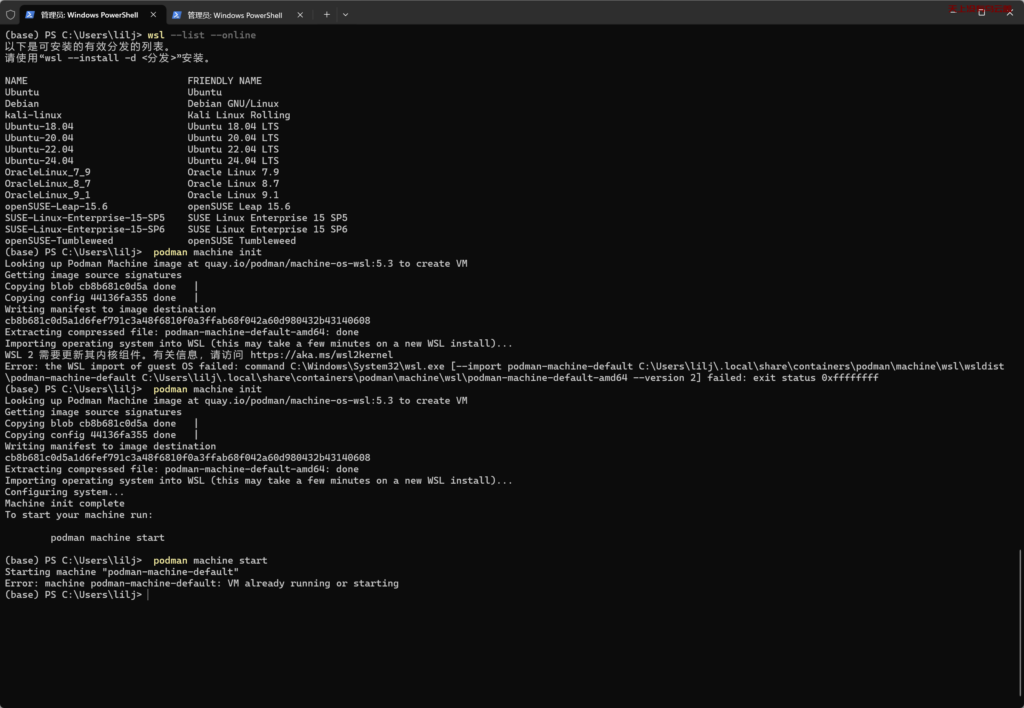
可以执行podman命令代表WSL和podman都装好了,可以打开PodmanDesktop进行创建容器。
open-webui
下载镜像太费劲了,直接在网络好机器上面下载好image,然后使用下面的命令方式把image导入到PC上
docker save -o [保存路径/文件名] [镜像名]
docker load -i [文件路径]
有了镜像启动服务
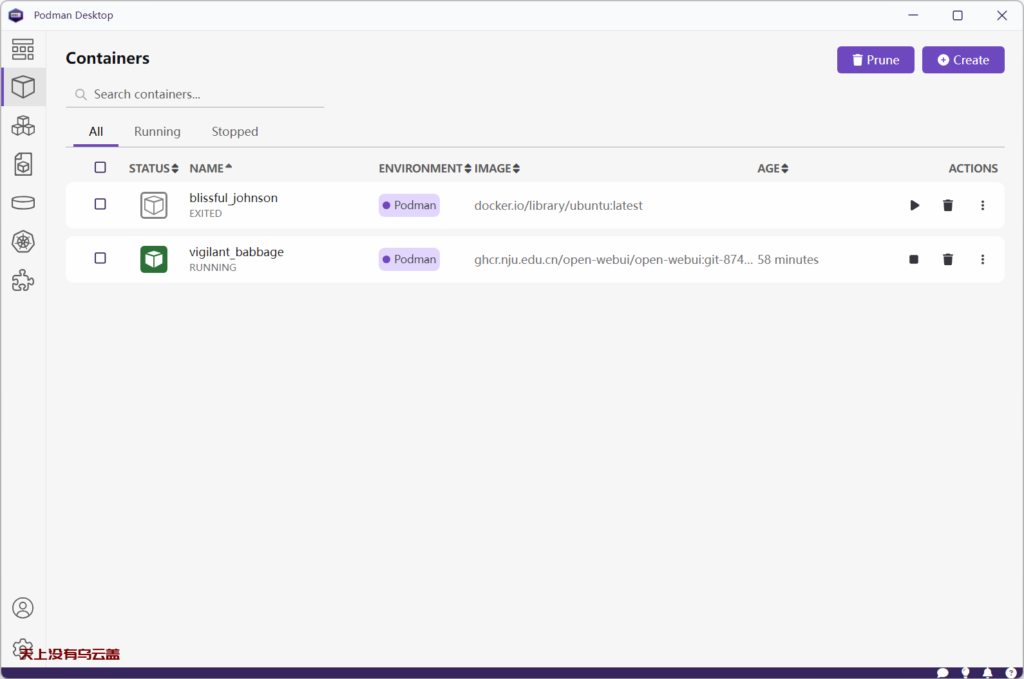
打开webui,发现访问不了本地模型
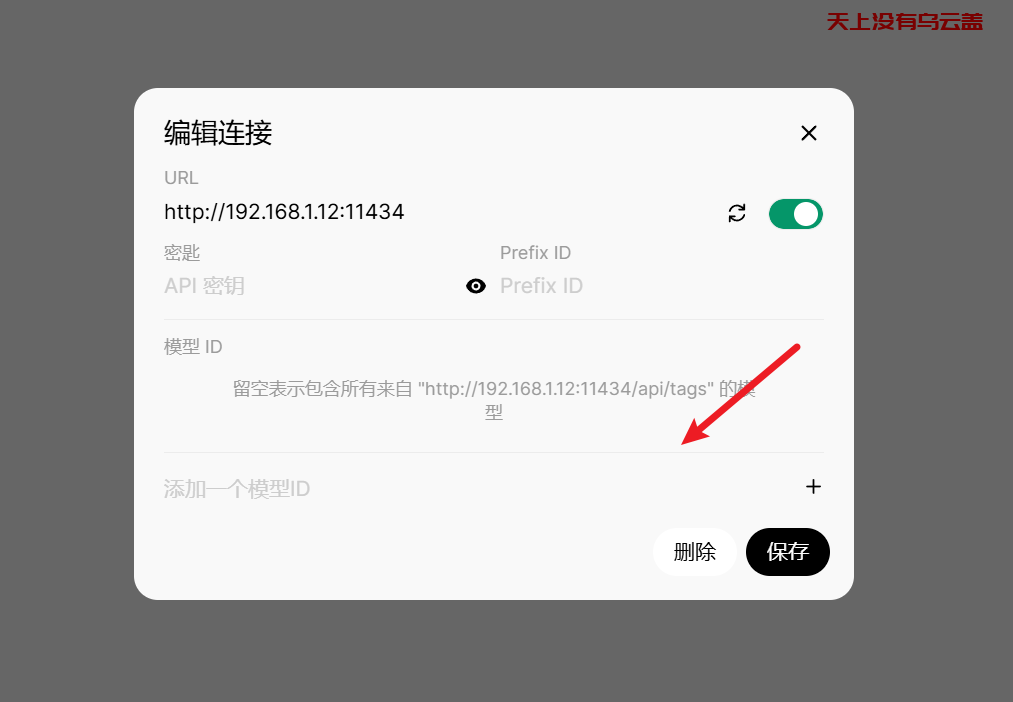
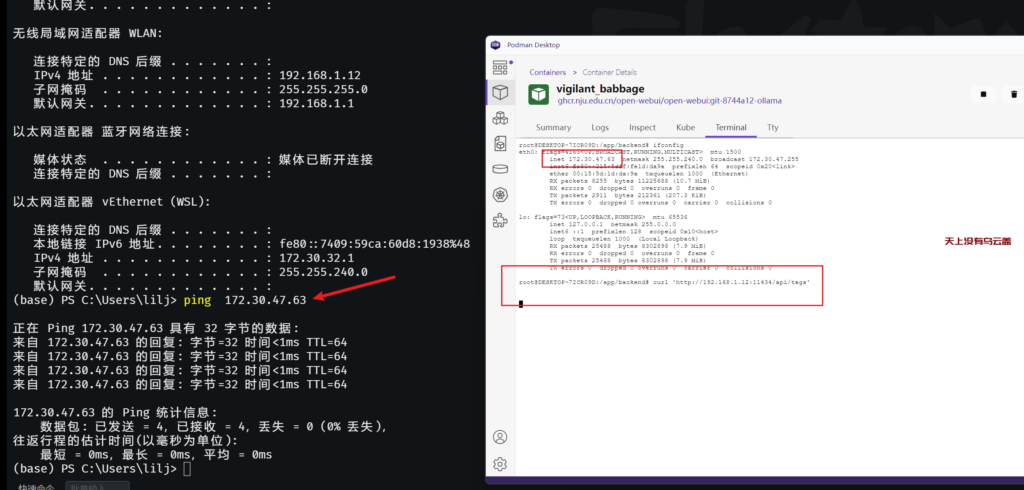
在物理机上能ping通webui的IP,但在webui容器中访问不了http://192.168.1.12:11434/api/tags ollama api,比较奇怪,webui安装一些网络工具方便进行排查
apt install procps net-tools iputils-ping排查到最后发现是windows防火墙导致的,把11434、8080端口加到规则中,在webui中可以访问通ollama api了,如下:
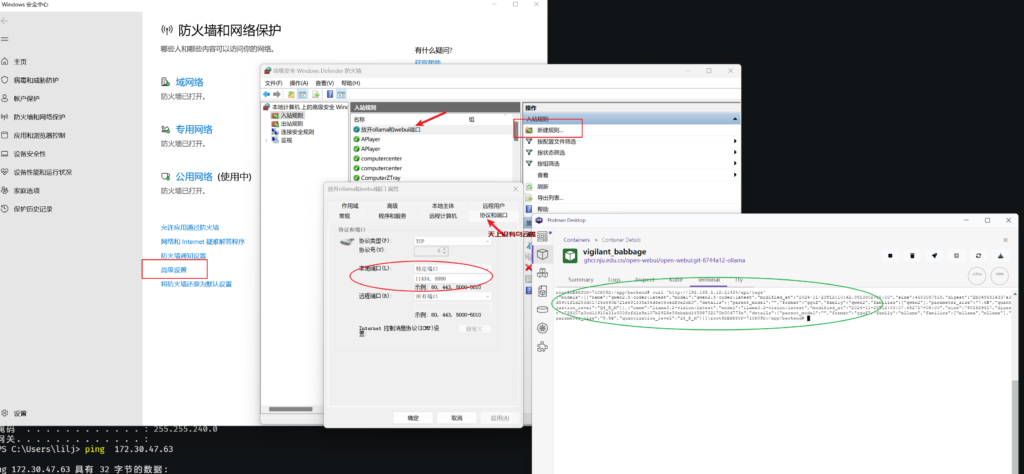
打开webui也可以交互式使用本地模型了

把模型放到GPU上
到现在模型都是运行在CPU上,查了一下要是运行在GPU上需要安装CUDA,从官网下载对应系统版本的CUDA,重启ollama后就可以了。
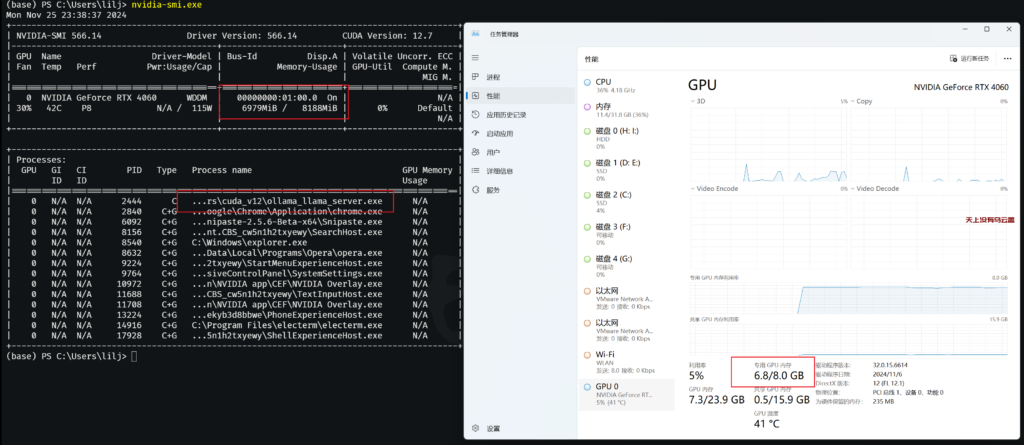
测一下GPU上token的生成速度
参考https://blog.csdn.net/freewebsys/article/details/136923371博主的代码,修改一下
# coding=utf-8
"""
代码测试工具:
python3 test_throughput.py --api-address http://localhost:8000 --model-name chatglm3-6b --n-thread 10
"""
import argparse
import json
import requests
import threading
import time
def main():
"""
主函数,用于测试API吞吐量。
该函数会根据命令行参数初始化API地址、模型名称和线程数,然后创建多个线程同时向API发送请求,
以测试API的吞吐量。函数会计算所有线程生成的单词总数,并计算每秒生成的单词数。
"""
# 设置请求头,包括用户代理和内容类型
headers = {"User-Agent": "openai client", "Content-Type": "application/json"}
# 构建请求负载,包括模型名称、用户消息和温度参数
ploads = {
"model": args.model_name,
"messages": [{"role": "user", "content": "写一个获取北京天气的Python代码"}],
"temperature": 0.7,
}
# 获取线程API地址
thread_api_addr = args.api_address
def send_request(results, i):
"""
发送请求函数。
该函数由每个线程调用,向API发送请求并处理响应。函数会打印线程编号、请求的API地址、
响应文本和生成的单词数。
参数:
- results: 用于存储所有线程结果的列表。
- i: 线程编号。
"""
print(f"thread {i} goes to {thread_api_addr}")
response = requests.post(
thread_api_addr + "/v1/chat/completions",
headers=headers,
json=ploads,
stream=False,
)
print(response.text)
response_new_words = json.loads(response.text)["usage"]["completion_tokens"]
#error_code = json.loads(response.text)["error_code"]
print(f"=== Thread {i} ===, words: {response_new_words} ")
results[i] = response_new_words
# use N threads to prompt the backend
tik = time.time()
threads = []
results = [None] * args.n_thread
for i in range(args.n_thread):
t = threading.Thread(target=send_request, args=(results, i))
t.start()
# time.sleep(0.5)
threads.append(t)
for t in threads:
t.join()
print(f"Time (POST): {time.time() - tik} s")
n_words = sum(results)
time_seconds = time.time() - tik
print(
f"Time (Completion): {time_seconds}, n threads: {args.n_thread}, "
f"throughput: {n_words / time_seconds} words/s."
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--api-address", type=str, default="http://192.168.1.12:11434")
parser.add_argument("--model-name", type=str, default="qwen2.5-coder:latest")
parser.add_argument("--n-thread", type=int, default=10)
args = parser.parse_args()
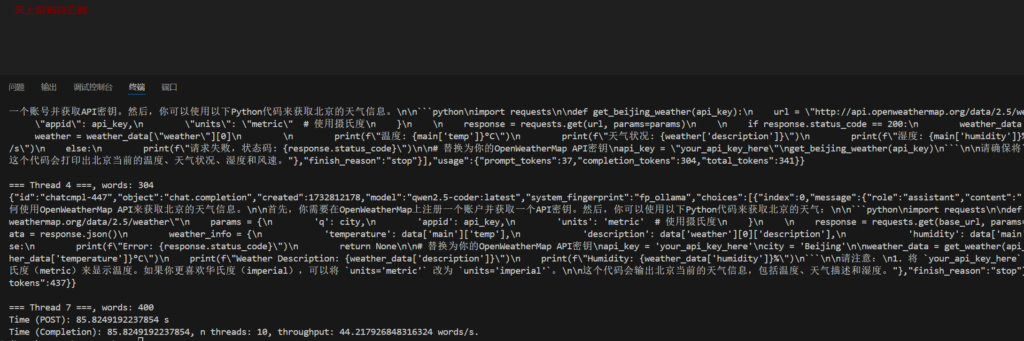
main()使用qwen2.5-coder:latest “content”: “写一个获取北京天气的Python代码” 进行测试, token的产生速度挺快的。
多模态大模型
Meta发布的LLaMA3.2 vision多模态大模型,ollama也有了https://ollama.com/library/llama3.2-vision,下来尝鲜,这个识别太赞了。


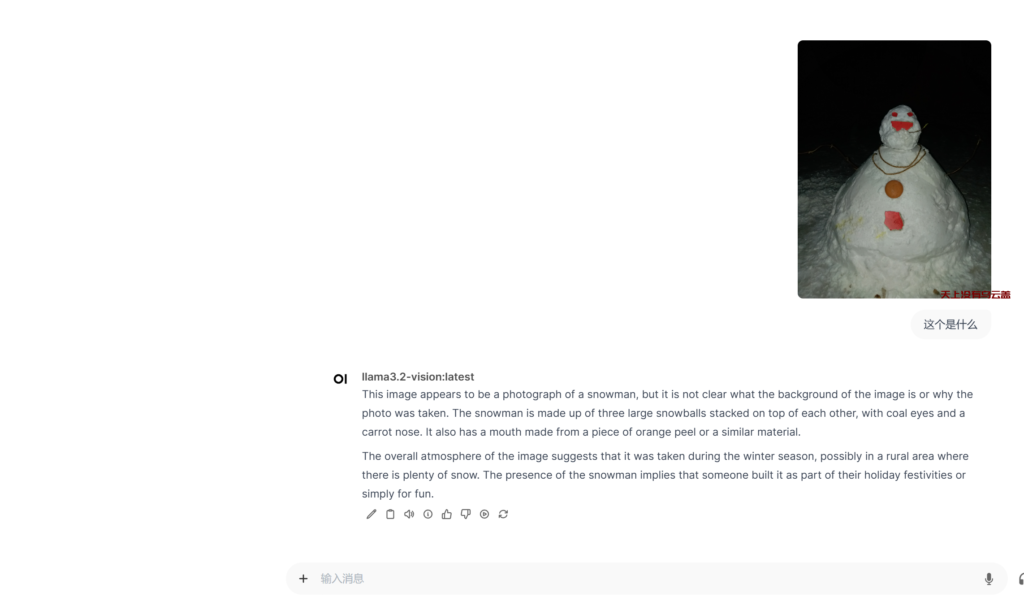
写在最后
在PC上安装podman和webui挺麻烦的,一点都不“丝滑“。极客时间12|LLaMA 3.2 Vision 将如何颠覆智能文档处理领域? 详细讲解过,llama3.2-vision 能够直接处理图片数据,理解其内容并生成自然语言描述。可以自己·基于此构建内部的智能文档处理IDP智能化业务流程。
就到这里吧,后面在工作和学习中看看如何应用这个大模型。