
查…不了混淆的js
这入伏后天气真热,周日去朝阳公园待了一下午晚上回来就开始发烧了,感觉像中暑了,但又没有那么难受。遇到查看混淆的js也不顺利,心情难免有些低落。
事件背景
很多的应用服务都会允许用户上传一些文件,比如图片、视频、音频等,这里面就有一些安全的风险。上周安全部门反馈有一个服务被黑产利用了,会传播一些恶意行为。根据提供的异常文件访问,特征如下
http://****/l0bya-w8r3j-85tjg.xhtml?id=QFGTGW ,一个xhtml后面跟一个id=***
这个xhtml的内容是
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" lang="en">
<head>
<meta charset="UTF-8" />
<script>
sessionStorage.clear()
</script>
</head>
<body>
</body>
<script type="text/javascript" charset="utf-8" src="https://xn--xkrx27b.xn--6qq986b3xl/assets/xml_js_config.js"></script>
<script type="text/javascript" charset="utf-8" src="https://xn--0929-kq4ja.xn--6qq986b3xl/assets/xml_js_config.js"></script>
<script type="text/javascript" charset="utf-8" src="https://xxxcode3.com/api/js_config/xml_js_config.js"></script>
</html>%行为分析
先把js下载下来
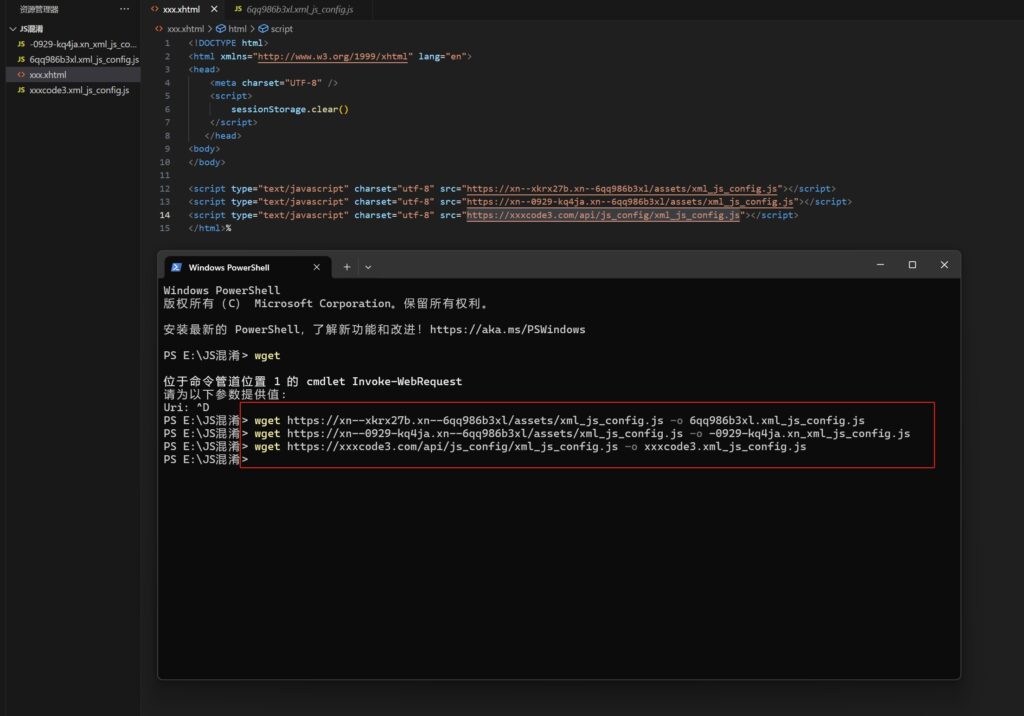
内容看起来缩进处理过,变量和函数都是不规则的字符,应该是经过混淆过的

直接请求这个xhtml会加载这三个js
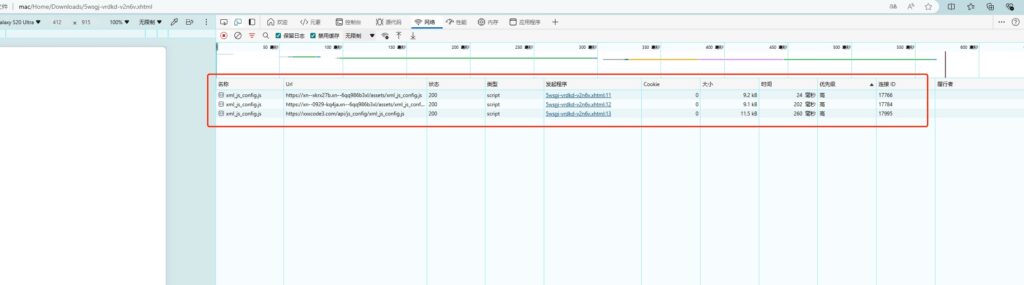
在chrome浏览器调试工具控制台能看到js执行后返回三个版本号
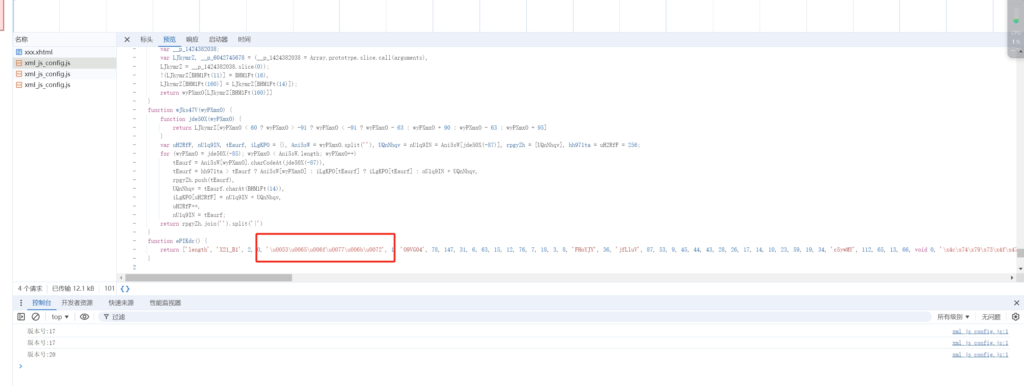
把chrome浏览器调试工具中返回的预览里面的js内容复制到网上解混淆的网站里面都无法完全还原混淆。
比较郁闷,了解了一下js常用的混淆方式,有常量混淆、数组混淆、数组乱序、花指令、流程平坦化等,随便几种大杂烩一下这js代码就完全没有办法看了。
断点调试
手动还原了一些js函数,效果不是很理想,受限于这个js函数执行顺序没有办法直接捋清楚,暂时先分析一下这些js的行为。在chrome浏览器调试工具使用断点调试功能,把console打印版本号那块打上断点

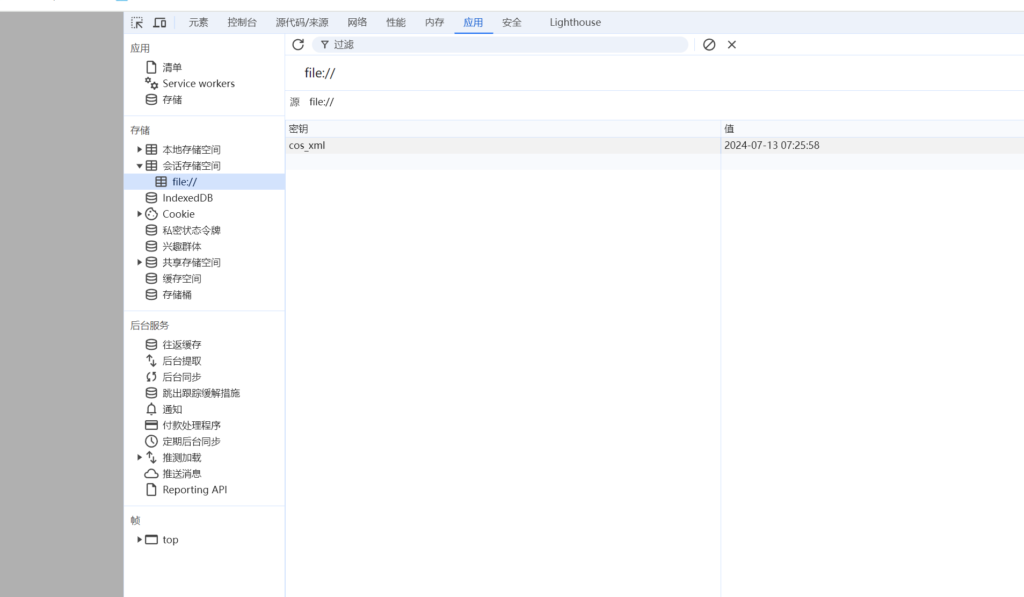
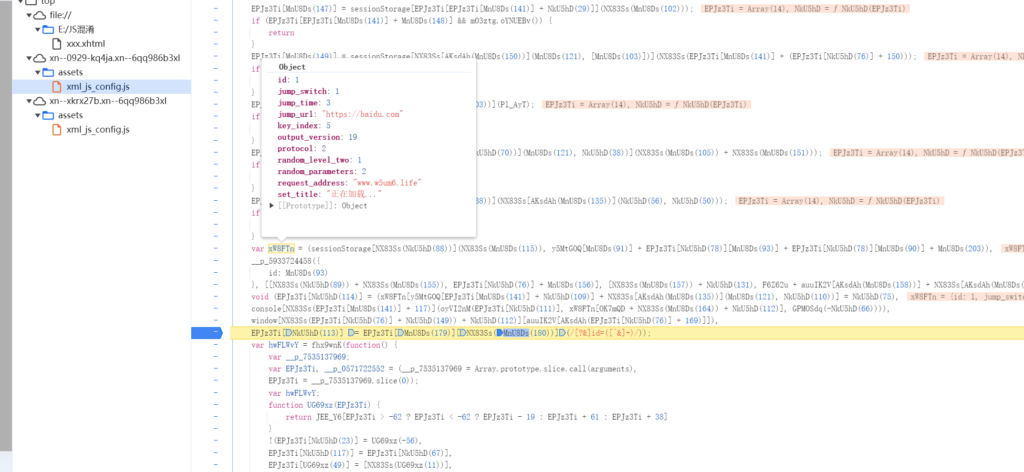
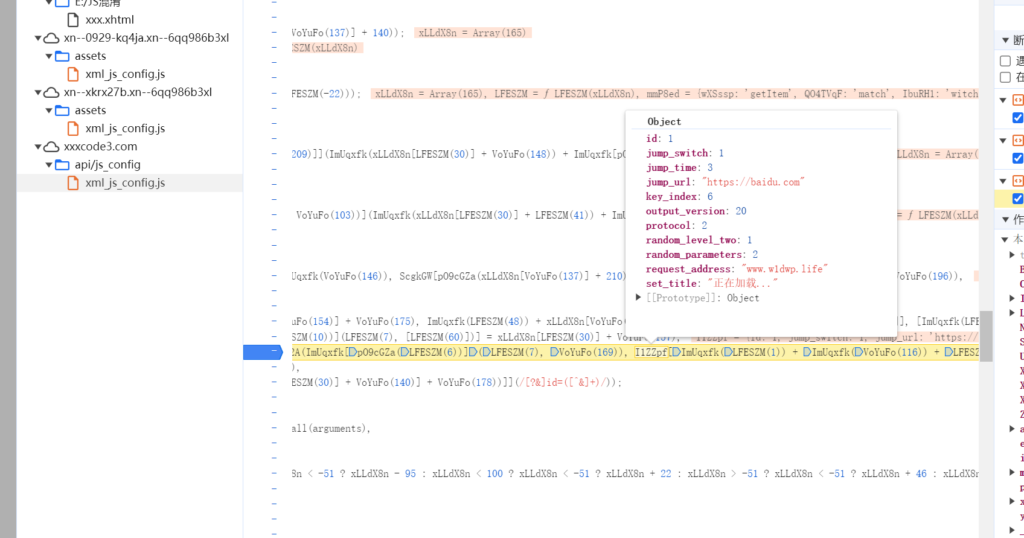
从三个js断点来看,相似的特征就是临近打印输出的对象里面有*.life的域名,sessionstorage存一个秘钥信息,怀疑这三个js会去请求这里面的三个life域名
https://www.w1dwp.life
https://www.psb2b.life
https://www.w5um6.life比较容易的,抓包验证一下(图里说的抓到http包不正确,抓到了tcp包),可以看到断点调试的时候执行一个js就会访问一个.life域名,这三个life域名都是一组固定的IP 14.128.41.0/24
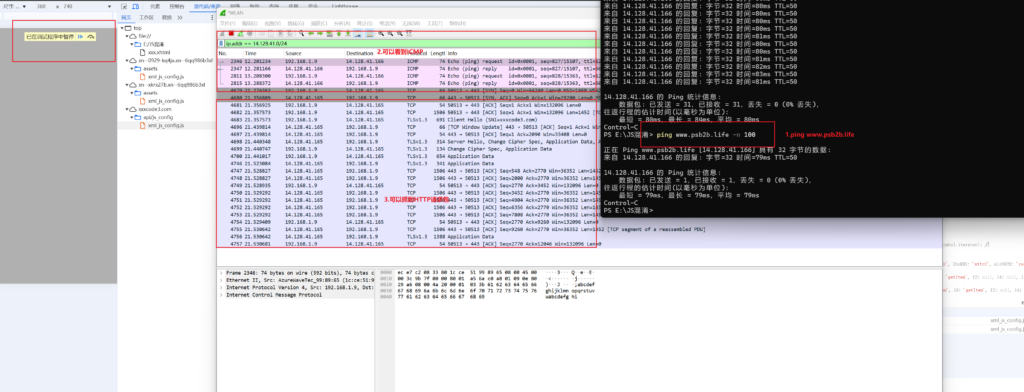
JWT
在wireshark里面无法解析TLSV1.3包,看不到请求的具体URL是什么,根据上面的sessionstorage信息去构建一个请求,比如https://www.w1dwp.life/web_urk_xml,https://www.psb2b.life/cos_xml,返回的都是下面的内容:
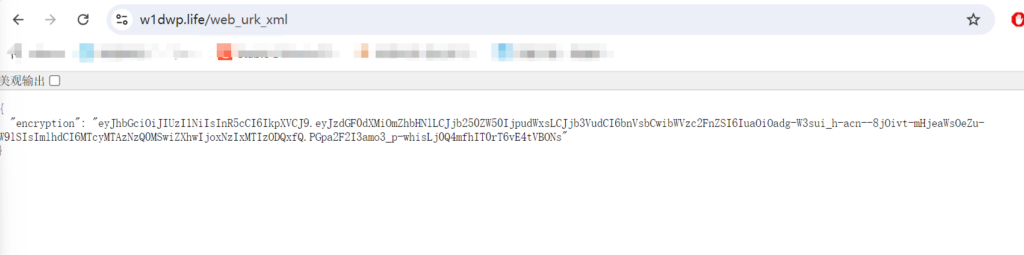
特别像JSON Web Token,有一个固定的特征 eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzd
看起来像JWT(JWT详解(组成,工作原理,优缺点,续签问题,删除但有效问题)),去https://jwt.io/#debugger-io 解析一下能看出来
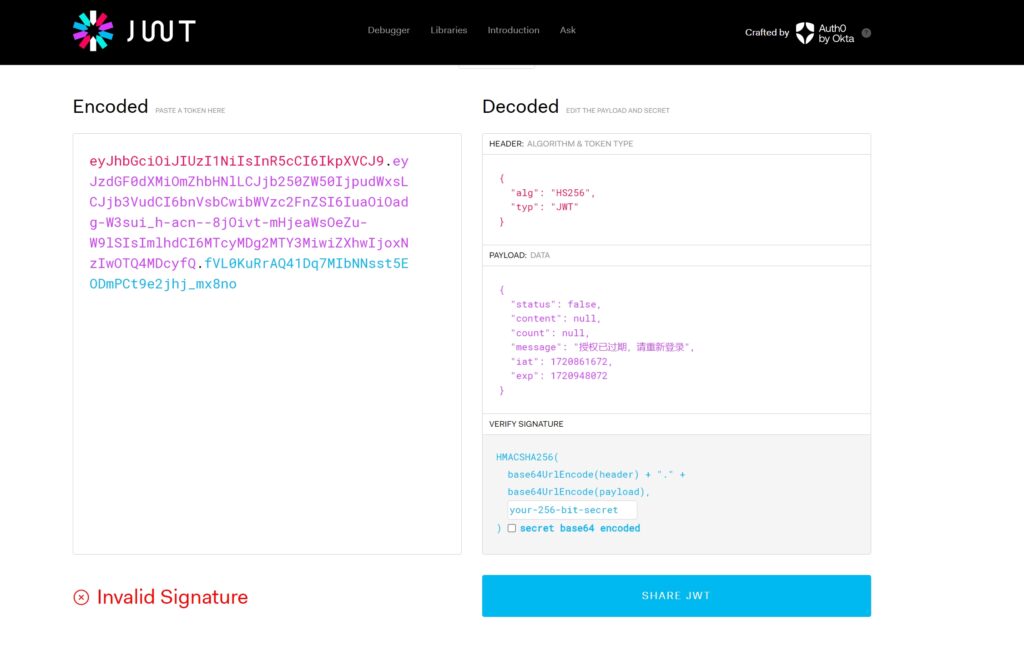
…………
Punycode
在分析过程中还发现一个好玩的,这三个js有两个域名是
https://xn--xkrx27b.xn--6qq986b3xl/assets/xml_js_config.js
https://xn--0929-kq4ja.xn--6qq986b3xl/assets/xml_js_config.js直接在浏览器打开的话是


挺好玩的,搜了一下
#Punycode是一个根据RFC 3492标准而制定的编码系统,主要用於把域名从地方语言所采用的Unicode编码转换成为可用于DNS系统的编码。Punycode可以防止IDN欺骗。
#国际化域名IDNs
#早期的DNS(Domain Name System)是只支持英文域名解析。在IDNs(国际化域名Internationalized Domain Names)推出以后,为了保证兼容以前的DNS,所以,对IDNs进行punycode转码,转码后的punycode就由26个字母+10个数字,还有“-”组成。
#浏览器对punycode的支持
#目前,因为操作系统的核心都是英文组成,DNS服务器的解析也是由英文代码交换,所以DNS服务器上并不支持直接的中文域名解析,所有中文域名的解析都需要转成punycode码,然后由DNS解析punycode码。其实目前所说和各种浏览器完美支持中文域名,只是浏览器软里面主动加入了中文域名自动转码,不需要原来的再次安装中文域名转码控件来完成整个流程。如果在本地生成的话有两种方式
#https://docs.python.org/3.10/library/codecs.html#module-encodings.idna
#Unicode域名转ASCII域名
print('月华.我爱你'.encode('idna').decode())
#ASCII域名转Unicode域名
print('xn--xkrx27b.xn--6qq986b3xl'.encode().decode('idna'))
#If you need the IDNA 2008 standard from RFC 5891 and RFC 5895, use the third-party idna module.
import idna
#Unicode域名转ASCII域名
print(idna.encode('月华.我爱你'))
#ASCII域名转Unicode域名
print(idna.decode('xn--xkrx27b.xn--6qq986b3xl'))写在最后
到这里还是不知道这个xhtml具体能干啥?好气哦,AST原理也看了一下,发现难度有些高了。暂时先封禁了这类资源的访问,从访问侧暴力解决。
英格兰这混子踢法丢冠也不冤!