
轻触ollama
ollama+llama3
2024年ChatGPT迎来了井喷式发展,chatgpt相关应用层出不穷,chatgpt就像一位聪明睿智的老师,你提什么问题都可以回答,文学、代码等任何主题都可以。ChatGPT可以用于自然语言处理、机器翻译、对话系统、自动回复和智能客服等方面,通过人类语言直接与人交流,可以给用户提供更好的用户体验,继而实现节省人力和时间成本的目的。
后期开源的大模型层出不穷,大部分都无法直接运行在个人电脑(没有独立显卡的)上,这些模型运行通常需要大量的计算资源(特别是显卡)和复杂的配置部署。ollama的出现帮助用户快速在本地运行开源大模型,用户仅需要执行一条命令就可以本地运行开源大模型。2024年4月18日,meta开源了Llama 3大模型(8B和70B两个版本),ollama也很快进行了支持,可以快速本地化体验lllama3模型。

安装ollama
在自己电脑上ollama的安装运行比较简单,网上有很多的参考文章
Ollama 轻松玩转本地大模型,带你体验谷歌最强的gemma模型,部署私人ChatGPT
使用Ollama和OpenWebUI在CPU上玩转Meta Llama3-8B
在mac电脑上运行如下,操作比较简单,但是运行频繁的话占用系统资源特别高,CPU上运行大模型还是很耗费资源的。
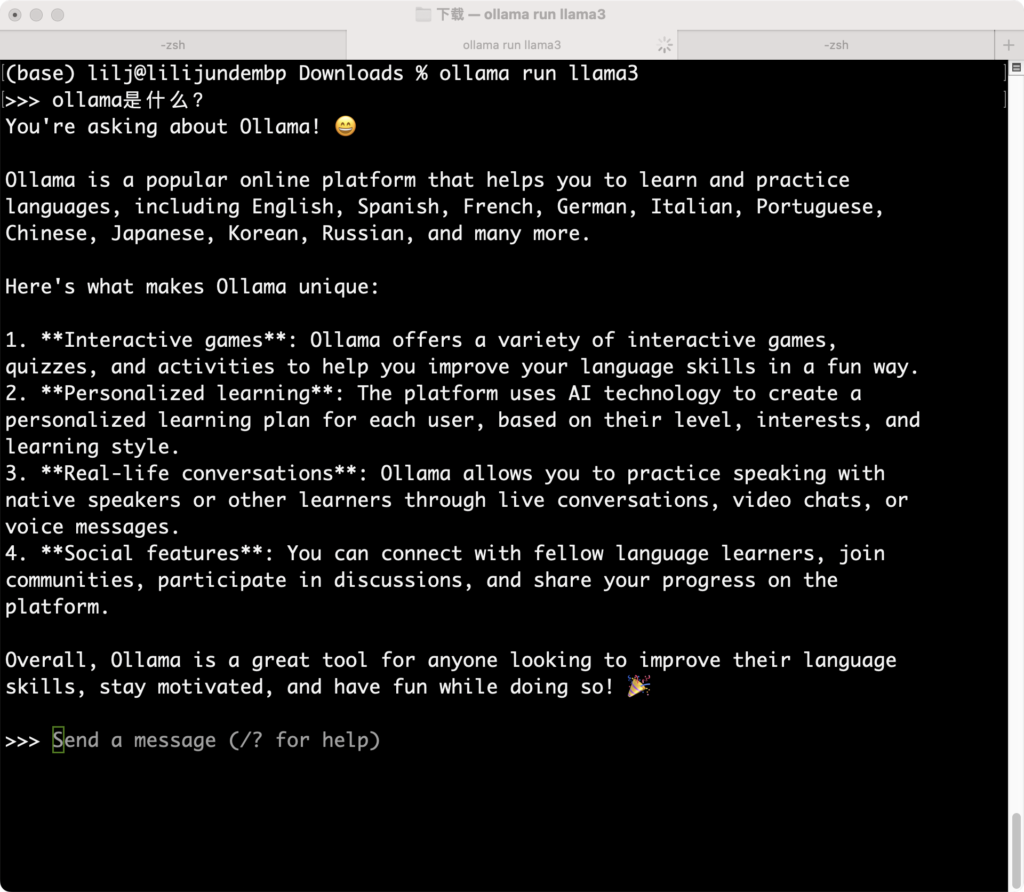

安装ollama遇到的问题
pull请求被reset掉
我们服务器有一些1080卡资源,尝试部署到GPU上看看速度咋样,Linux安装比较简单
curl -fsSL https://ollama.com/install.sh | sh启动ollama后进行pull llama3模型,提示网络连接被reset掉了


看起来像是被墙了,设置一个HTTP代理后继续pull还是不行,但是curl却是走代理了



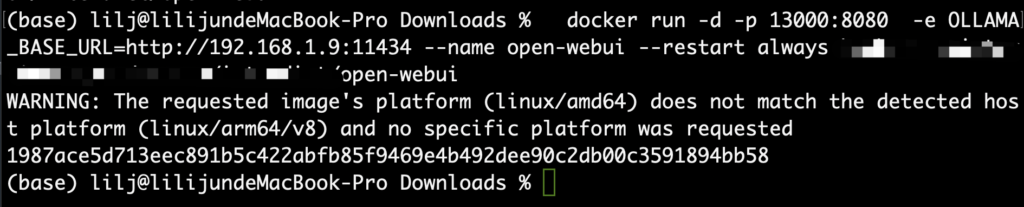
OLLAMA_HOST无法监听本地IP
mac Docker运行open-webui,访问本地IP ollama http://192.168.1.9:11434接口不通
在ollama issues可以看到对应的解决办法 https://github.com/ollama/ollama/issues/703
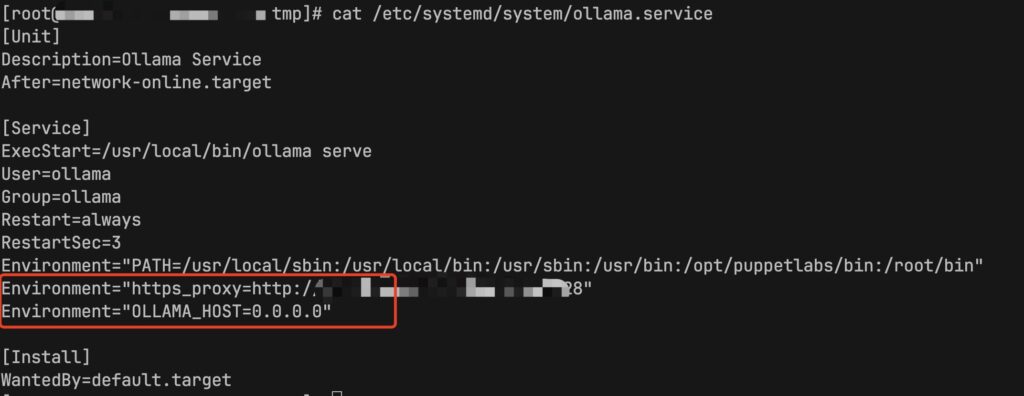
1、Linux ollama设置代理
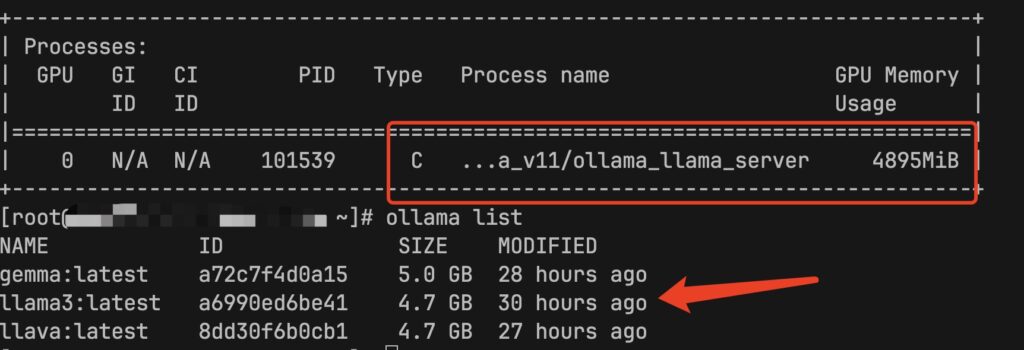
2、mac设置OLLAMA_HOST

CPU和GPU对比
GPU机器上token的输出速度CPU机器快很多,但是结果上有些不同,同一个问题
”写一个python脚本,获取当前登录系统的全部用户以及用户正在打开的进程名字“
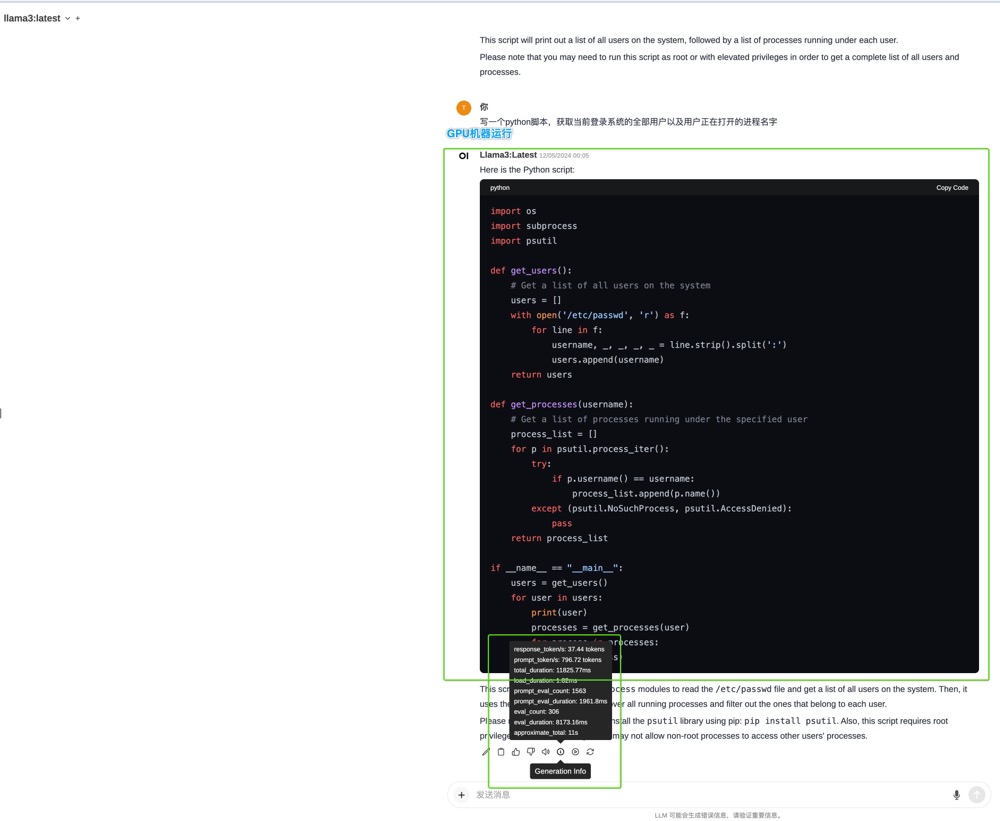
#GPU的结果
import os
import subprocess
import psutil
def get_users():
# Get a list of all users on the system
users = []
with open('/etc/passwd', 'r') as f:
for line in f:
username, _, _, _, _ = line.strip().split(':')
users.append(username)
return users
def get_processes(username):
# Get a list of processes running under the specified user
process_list = []
for p in psutil.process_iter():
try:
if p.username() == username:
process_list.append(p.name())
except (psutil.NoSuchProcess, psutil.AccessDenied):
pass
return process_list
if __name__ == "__main__":
users = get_users()
for user in users:
print(user)
processes = get_processes(user)
for process in processes:
print(process)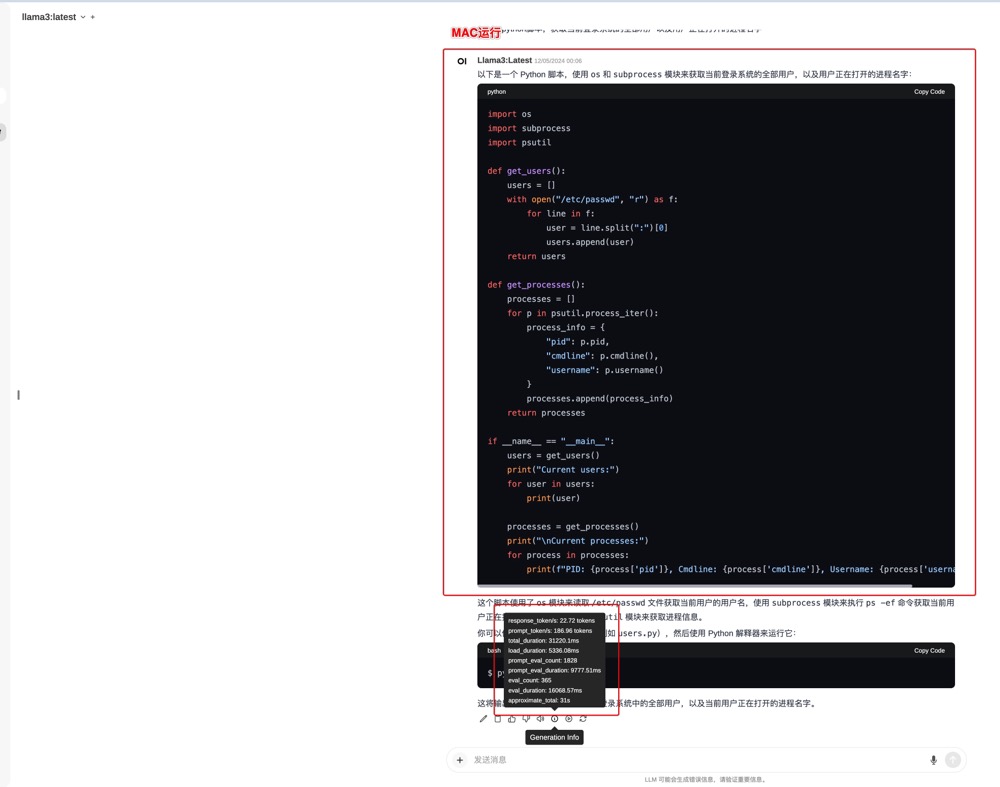
#CPU的结果
import os
import subprocess
import psutil
def get_users():
users = []
with open("/etc/passwd", "r") as f:
for line in f:
user = line.split(":")[0]
users.append(user)
return users
def get_processes():
processes = []
for p in psutil.process_iter():
process_info = {
"pid": p.pid,
"cmdline": p.cmdline(),
"username": p.username()
}
processes.append(process_info)
return processes
if __name__ == "__main__":
users = get_users()
print("Current users:")
for user in users:
print(user)
processes = get_processes()
print("\nCurrent processes:")
for process in processes:
print(f"PID: {process['pid']}, Cmdline: {process['cmdline']}, Username: {process['username']}")GPU输出的脚本在服务器执行报错了,但是CPU输出的脚本在服务器执行很顺利,有些奇怪!~
写在最后
ollama这种可以部署大模型的工具提升了工作效率,从之前搜索的大量结果中快速得到有效和想要的结果,减少重复编码,提升编码效率,从此计算机过剩的性能有了用处。