
遇到的字符集问题
出现报错
有个老的文件管理系统还是用的svn,换到新机房机器上执行svn up会提示下面的报错

已知的原机器和新机器在系统版本、svn版本上有变化,用户环境变量上LANG结果一致
$ env| grep LANG
LANG=en_US.UTF-8
LC_CTYPE 为空从网上搜了解决方法,将export LANG=zh_CN.UTF-8 改为 export LC_CTYPE=en_US.UTF-8
复现报错
找一台A机器系统版本和上面报错机器的一致,svn co文件目录后,export LANG=zh_CN.UTF-8 后再执行svn up就会报之前的那种错误,如下图:
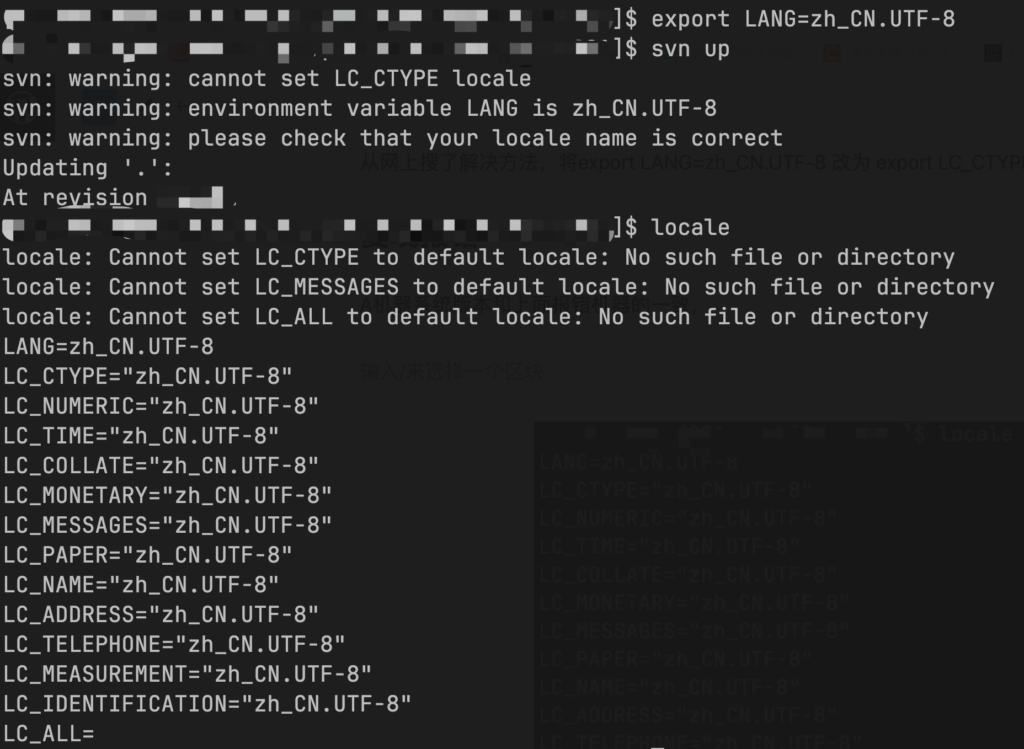
找了一台B机器和之前老的机器系统版本一致,svn co文件目录后,export LANG=zh_CN.UTF-8 后执行svn up 正常未出现报错,如下图:
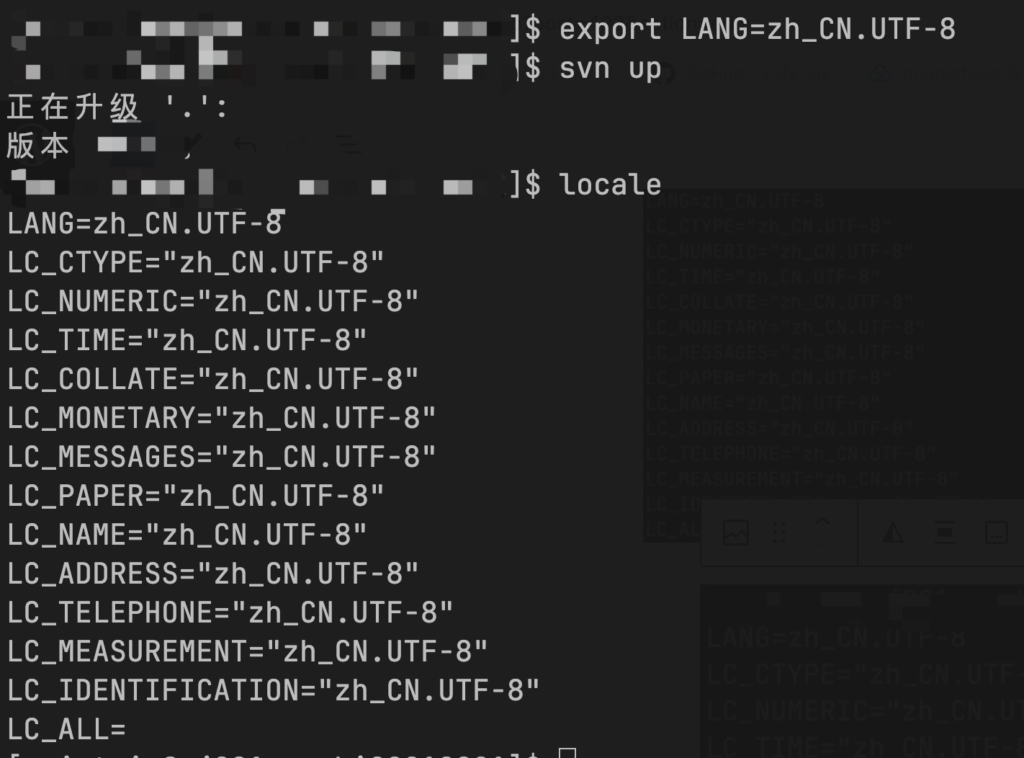
对比一下两个系统安装的字符编码
#先获取A和B机器的已安装的字符编码
A机器执行locale -a > /tmp/A_machine_locale
B机器执行locale -a > /tmp/B_machine_locale
#对比两个机器字符编码
grep -wf A_machine_locale B_machine_locale | grep zh_CN
两个机器的字符编码结果交集中没有zh_CN
#A机器没有安装zh_CN字符编码
grep zh_CN A_machine_locale
结果为空
#B机器安装了zh_CN字符编码
grep zh_CN B_machine_locale
zh_CN
zh_CN.gb18030
zh_CN.gb2312
zh_CN.gbk动手解决
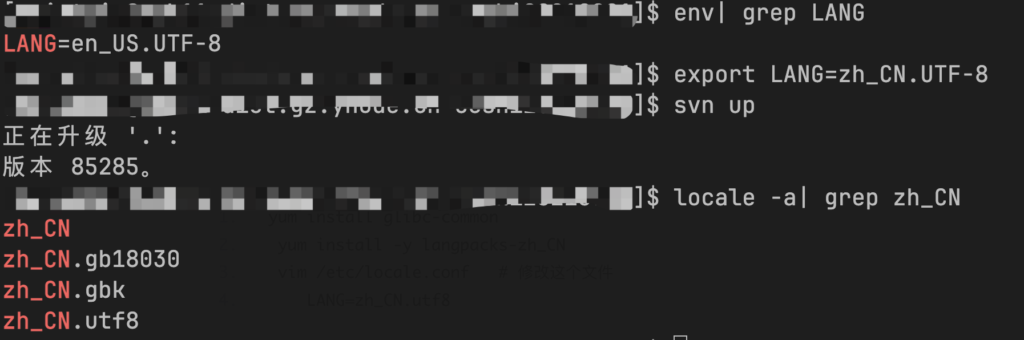
A机器安装一下zh_CN字符编码,需要安装glibc-common、langpacks-zh_CN这两个包
再次执行svn up报错信息没有了~
en_US.UTF-8与zh_CN.utf8的区别
en_US.UTF-8和zh_CN.UTF-8叫做字符集,是一种语言环境,在编程中设置的utf-8是一种编码方式。
- en_US.UTF-8 是英文的 UTF-8 编码,支持英文及其他拉丁字母语种,以及特殊符号等字符。该字符集可以在 Unix/Linux 和 MacOS 等操作系统上使用,并兼容 C.UTF-8 。
- zh_CN.UTF-8 是中文UTF-8 编码。它主要支持汉字、拼音、符号以及少量英文单词。中文系统在 Linux/Unix 系统上会默认安装该编码。zh_CN.UTF-8 用于中文的应用程序、网站, 显示中文用这个更好兼容
国人的系统大部分都是这个编码字符集,我个人的mac系统是中文的 ,对应的LANG就是zh_CN.UTF-8

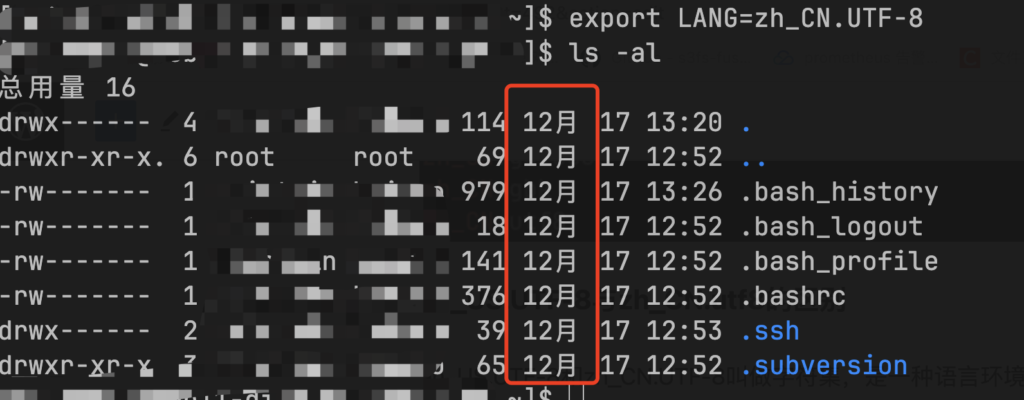
在A机器上设置export LANG=zh_CN.UTF-8,ls -al的时候看到的日期就变成了中文12月
LANG
转载一篇文章 Linux的locale、LC_ALL和LANG
LANG是LC_*的默认值,LC_*变量可以单独设置而可以与LANG不同。而LC_ALL比LC_*的优先级别高,设置完LC_ALL之后,会强制重置LC_*各个值,如果不将LC_ALL重新设置为空,则再无法设置LC_*的单个值 。
写在最后
深入了解问题背后的本质进而提升思考的深度,将自己变为旅行者而不是游客。