
MongoDB WiredTiger 引擎压缩算法选型实践

六一快乐
今天是六一儿童节,不管年龄多大,心中始终有一颗童心。
WiredTiger存储引擎背景
存储引擎是 MongoDB 负责管理数据的主要组件,WiredTiger 存储引擎是默认存储引擎(自 MongoDB 3.2 起)。具体可以参考:https://www.mongodb.com/zh-cn/docs/v5.0/core/wiredtiger/。利用 WiredTiger,MongoDB 能够支持对所有集合和索引进行压缩。压缩能够最大限度减少存储使用量,但会消耗额外的 CPU 资源。
| 对象 | 默认压缩 |
|---|---|
| 集合(Collection) | snappy(高速块压缩) |
| 索引(Index) | prefix compression(前缀去重) |
WiredTiger 支持三种集合压缩算法:
| 算法 | 特点 |
|---|---|
| snappy | 默认,速度快,CPU 消耗低 |
| zlib | 压缩率高,但速度慢 |
| zstd | v4.2+ 引入,兼顾压缩率与速度 |
在真实业务中,压缩策略需要在 读写比例、存储成本、CPU 余量 三者之间权衡。
测试三种压缩算法
测试目标
使用Python来简单对比一下三种压缩算法,对比 snappy / zlib / zstd 在 MongoDB 文档场景下的表现,为生产环境压缩算法选型提供依据。
测试环境
| 项目 | 配置 |
|---|---|
| OS | macOS(ARM) |
| CPU | Apple M1 |
| Python | 3.11 |
| 依赖 | python-snappy==0.6.1,zstandard==0.22.0 |
| MongoDB | ≥ 4.2(仅作为背景,测试为应用层压缩) |
⚠️ 说明:
本测试为 应用层内存压缩,与 WiredTiger 内部
blockCompressor行为不完全等价,但趋势一致,可用于选型参考。MongoDB 4.2+ 支持 zstd,默认压缩级别由 WiredTiger 控制(通常为 3 或 6,不同版本略有差异)。
本次测试采用 zstd level=3,与 MongoDB 默认行为对齐。
安装:pip install python-snappy zstandard使用脚本生成 100MB JSONL 文件,模拟真实 MongoDB 文档结构:
- 多种数据类型(字符串、数值、布尔、日期)
- 嵌套文档(address)
- 数组(items / tags)
#!/usr/bin/env python3
"""
生成 MongoDB 文档测试文件
- 模拟真实 MongoDB 文档结构
- 包含嵌套文档、数组、各种数据类型
- 生成指定大小的 JSON 文件
"""
import json
import random
import string
import datetime
import sys
from typing import List, Dict, Any
def generate_mongodb_document(doc_id: int) -> Dict[str, Any]:
"""生成一个模拟 MongoDB 文档"""
# 随机生成字符串
def random_string(length: int) -> str:
return ''.join(random.choices(string.ascii_letters + string.digits, k=length))
# 随机生成日期
def random_date(start_year=2020, end_year=2024):
year = random.randint(start_year, end_year)
month = random.randint(1, 12)
day = random.randint(1, 28)
return datetime.datetime(year, month, day)
# 生成嵌套文档
address = {
"street": f"{random.randint(100, 9999)} {random.choice(['Main', 'Oak', 'Pine', 'Maple'])} St",
"city": random.choice(["New York", "London", "Tokyo", "Beijing", "Sydney"]),
"state": random_string(2).upper(),
"zip": f"{random.randint(10000, 99999)}",
"coordinates": {
"lat": round(random.uniform(-90, 90), 6),
"lng": round(random.uniform(-180, 180), 6)
}
}
# 生成数组
tags = random.sample([
"mongodb", "database", "nosql", "performance", "testing",
"python", "json", "compression", "benchmark", "storage"
], k=random.randint(2, 5))
# 生成订单项数组
items = []
for i in range(random.randint(1, 5)):
items.append({
"item_id": random.randint(1000, 9999),
"product": random_string(10),
"price": round(random.uniform(10.0, 500.0), 2),
"quantity": random.randint(1, 10),
"metadata": {
"category": random.choice(["electronics", "clothing", "books", "home"]),
"in_stock": random.choice([True, False])
}
})
# 完整文档
document = {
"_id": f"doc_{doc_id:08d}",
"user_id": random.randint(100000, 999999),
"session_id": random_string(32),
"created_at": random_date(),
"updated_at": datetime.datetime.now(),
"is_active": random.choice([True, False]),
"priority": random.choice(["low", "medium", "high"]),
"score": round(random.uniform(0.0, 100.0), 2),
"count": random.randint(0, 1000),
"balance": round(random.uniform(-1000.0, 10000.0), 2),
"email": f"user{doc_id}@example.com",
"phone": f"+1{random.randint(1000000000, 9999999999)}",
"address": address,
"tags": tags,
"items": items,
"metadata": {
"source": random.choice(["web", "mobile", "api"]),
"version": f"{random.randint(1, 5)}.{random.randint(0, 9)}.{random.randint(0, 9)}",
"features": {
"feature_a": random.choice([True, False]),
"feature_b": random.choice([True, False]),
"feature_c": random.choice([True, False])
}
},
"raw_data": random_string(200) # 模拟原始数据字段
}
return document
def generate_mongodb_test_file(
output_file: str = "mongodb_test_data.json",
target_size_mb: float = 100.0,
documents_per_batch: int = 1000
) -> None:
"""
生成 MongoDB 测试文件
Args:
output_file: 输出文件名
target_size_mb: 目标文件大小(MB)
documents_per_batch: 每批生成的文档数
"""
print(f"开始生成 MongoDB 测试文件: {output_file}")
print(f"目标大小: {target_size_mb} MB")
target_size_bytes = int(target_size_mb * 1024 * 1024)
current_size = 0
doc_id = 0
batch_count = 0
with open(output_file, 'w', encoding='utf-8') as f:
# 写入 JSON 数组开始
f.write('[\n')
while current_size < target_size_bytes:
batch = []
for _ in range(documents_per_batch):
doc = generate_mongodb_document(doc_id)
batch.append(json.dumps(doc, default=str))
doc_id += 1
# 写入批次
if batch_count > 0:
f.write(',\n')
f.write(',\n'.join(batch))
# 更新大小和计数
batch_json = ',\n'.join(batch)
current_size += len(batch_json.encode('utf-8'))
batch_count += 1
# 显示进度
progress = (current_size / target_size_bytes) * 100
print(f"\r进度: {progress:.1f}% ({current_size/1024/1024:.1f} MB)", end='', flush=True)
# 检查是否达到目标大小
if current_size >= target_size_bytes:
break
# 写入 JSON 数组结束
f.write('\n]')
# 最终文件信息
actual_size = current_size / 1024 / 1024
print(f"\n\n生成完成!")
print(f"文件: {output_file}")
print(f"大小: {actual_size:.2f} MB")
print(f"文档数: {doc_id:,}")
print(f"平均每文档大小: {actual_size/doc_id*1024:.2f} KB")
def generate_jsonl_file(
output_file: str = "mongodb_test_data.jsonl",
target_size_mb: float = 100.0
) -> None:
"""
生成 JSON Lines 格式文件(每行一个文档,更适合 MongoDB 导入)
"""
print(f"开始生成 MongoDB JSONL 测试文件: {output_file}")
print(f"目标大小: {target_size_mb} MB")
target_size_bytes = int(target_size_mb * 1024 * 1024)
current_size = 0
doc_id = 0
with open(output_file, 'w', encoding='utf-8') as f:
while current_size < target_size_bytes:
doc = generate_mongodb_document(doc_id)
line = json.dumps(doc, default=str) + '\n'
f.write(line)
current_size += len(line.encode('utf-8'))
doc_id += 1
# 显示进度
if doc_id % 1000 == 0:
progress = (current_size / target_size_bytes) * 100
print(f"\r进度: {progress:.1f}% ({current_size/1024/1024:.1f} MB, {doc_id:,} 文档)",
end='', flush=True)
# 最终文件信息
actual_size = current_size / 1024 / 1024
print(f"\n\n生成完成!")
print(f"文件: {output_file}")
print(f"大小: {actual_size:.2f} MB")
print(f"文档数: {doc_id:,}")
print(f"平均每文档大小: {actual_size/doc_id*1024:.2f} KB")
print(f"\n导入 MongoDB 命令:")
print(f"mongoimport --db test --collection docs --file {output_file} --jsonArray")
if __name__ == "__main__":
# 生成 JSON 数组格式(适合压缩测试)
generate_mongodb_test_file(
output_file="mongodb_test_data.json",
target_size_mb=100.0
)
print("\n" + "="*60 + "\n")
# 生成 JSON Lines 格式(适合 MongoDB 导入)
generate_jsonl_file(
output_file="mongodb_test_data.jsonl",
target_size_mb=100.0
)
{
"_id": "doc_00001234",
"user_id": 567890,
"session_id": "AbCdEfGhIjKlMnOpQrStUvWxYz123456",
"created_at": "2023-05-15T00:00:00",
"is_active": true,
"priority": "high",
"score": 87.5,
"balance": 1234.56,
"email": "user1234@example.com",
"address": {
"street": "123 Main St",
"city": "New York",
"coordinates": {"lat": 40.7128, "lng": -74.0060}
},
"tags": ["mongodb", "performance", "testing"],
"items": [
{
"item_id": 5678,
"product": "WidgetX",
"price": 99.99,
"metadata": {"category": "electronics"}
}
]
}单条文档示例:
{
"_id": "doc_00001234",
"user_id": 567890,
"session_id": "AbCdEfGhIjKlMnOpQrStUvWxYz123456",
"created_at": "2023-05-15T00:00:00",
"is_active": true,
"priority": "high",
"score": 87.5,
"balance": 1234.56,
"email": "user1234@example.com",
"address": {
"street": "123 Main St",
"city": "New York",
"coordinates": {"lat": 40.7128, "lng": -74.0060}
},
"tags": ["mongodb", "performance", "testing"],
"items": [
{
"item_id": 5678,
"product": "WidgetX",
"price": 99.99,
"metadata": {"category": "electronics"}
}
]
}测试方法
使用Deepseek生成测试脚本,具体如下:
import time
import snappy
import zstandard as zstd
import zlib
import sys
# ==================== 配置参数 ====================
TEST_FILE_PATH = "/Users/lilj/Desktop/work_python/day_1/mongodb_test_data.jsonl"
TEST_TIMES = 10
ZSTD_LEVEL = 3
ZLIB_LEVEL = 3
# ==================================================
def read_test_file(file_path):
try:
with open(file_path, "rb") as f:
return f.read()
except FileNotFoundError:
print(f"❌ 错误:文件未找到:\n{file_path}")
sys.exit(1)
def run_single_test(compress_func, decompress_func, data):
"""运行单次测试"""
start = time.time()
compressed = compress_func(data)
compress_time = time.time() - start
start = time.time()
decompressed = decompress_func(compressed)
decompress_time = time.time() - start
if data != decompressed:
raise ValueError("解压失败,数据不一致!")
return compress_time, decompress_time, len(compressed)
def main():
print("=" * 80)
print("压缩算法性能测试(10次取平均值)")
print(f"测试文件:{TEST_FILE_PATH}")
print("=" * 80)
data = read_test_file(TEST_FILE_PATH)
original_size = len(data)
print(f"原始文件大小:{original_size / 1024 / 1024:.2f} MB\n")
# 初始化结果
snappy_compress_times = []
snappy_decompress_times = []
snappy_compressed_size = None
zstd_compress_times = []
zstd_decompress_times = []
zstd_compressed_size = None
zlib_compress_times = []
zlib_decompress_times = []
zlib_compressed_size = None
zstd_cctx = zstd.ZstdCompressor(level=ZSTD_LEVEL)
zstd_dctx = zstd.ZstdDecompressor()
for i in range(TEST_TIMES):
print(f"正在运行第 {i+1}/{TEST_TIMES} 次测试...")
# Snappy
ct, dt, csize = run_single_test(
lambda d: snappy.compress(d),
lambda c: snappy.decompress(c),
data
)
snappy_compress_times.append(ct)
snappy_decompress_times.append(dt)
if snappy_compressed_size is None:
snappy_compressed_size = csize
# Zstd
ct, dt, csize = run_single_test(
lambda d: zstd_cctx.compress(d),
lambda c: zstd_dctx.decompress(c),
data
)
zstd_compress_times.append(ct)
zstd_decompress_times.append(dt)
if zstd_compressed_size is None:
zstd_compressed_size = csize
# zlib
ct, dt, csize = run_single_test(
lambda d: zlib.compress(d, level=ZLIB_LEVEL),
lambda c: zlib.decompress(c),
data
)
zlib_compress_times.append(ct)
zlib_decompress_times.append(dt)
if zlib_compressed_size is None:
zlib_compressed_size = csize
# 计算平均值
avg_snappy_compress = sum(snappy_compress_times) / TEST_TIMES * 1000
avg_snappy_decompress = sum(snappy_decompress_times) / TEST_TIMES * 1000
snappy_ratio = original_size / snappy_compressed_size
avg_zstd_compress = sum(zstd_compress_times) / TEST_TIMES * 1000
avg_zstd_decompress = sum(zstd_decompress_times) / TEST_TIMES * 1000
zstd_ratio = original_size / zstd_compressed_size
avg_zlib_compress = sum(zlib_compress_times) / TEST_TIMES * 1000
avg_zlib_decompress = sum(zlib_decompress_times) / TEST_TIMES * 1000
zlib_ratio = original_size / zlib_compressed_size
# 输出结果
print("\n" + "=" * 80)
print("最终测试结果(10次平均值)")
print("=" * 80)
print(f"{'算法':<12} {'平均压缩耗时(ms)':<18} {'平均解压耗时(ms)':<18} {'压缩比':<10} {'压缩后大小(MB)'}")
print("-" * 75)
print(f"{'Snappy':<12} {avg_snappy_compress:<18.2f} {avg_snappy_decompress:<18.2f} {snappy_ratio:<10.2f} {snappy_compressed_size/1024/1024:.2f}")
print(f"{'Zstd(l3)':<12} {avg_zstd_compress:<18.2f} {avg_zstd_decompress:<18.2f} {zstd_ratio:<10.2f} {zstd_compressed_size/1024/1024:.2f}")
print(f"{'zlib(l3)':<12} {avg_zlib_compress:<18.2f} {avg_zlib_decompress:<18.2f} {zlib_ratio:<10.2f} {zlib_compressed_size/1024/1024:.2f}")
print("\n💡 说明:")
print("1. 压缩比 = 原始大小 / 压缩后大小(数值越大压缩效果越好)")
print("2. 测试已验证解压数据与原始文件完全一致")
if __name__ == "__main__":
main()运行脚本:
#第一次
================================================================================
压缩算法性能测试(10次取平均值)
测试文件:/Users/lilj/Desktop/work_python/day_1/mongodb_test_data.jsonl
================================================================================
原始文件大小:100.00 MB
正在运行第 1/10 次测试...
正在运行第 2/10 次测试...
正在运行第 3/10 次测试...
正在运行第 4/10 次测试...
正在运行第 5/10 次测试...
正在运行第 6/10 次测试...
正在运行第 7/10 次测试...
正在运行第 8/10 次测试...
正在运行第 9/10 次测试...
正在运行第 10/10 次测试...
================================================================================
最终测试结果(10次平均值)
================================================================================
算法 平均压缩耗时(ms) 平均解压耗时(ms) 压缩比 压缩后大小(MB)
---------------------------------------------------------------------------
Snappy 244.49 135.96 2.32 43.15
Zstd(l3) 261.45 74.14 3.55 28.16
zlib(l3) 985.68 278.56 3.26 30.63
💡 说明:
1. 压缩比 = 原始大小 / 压缩后大小(数值越大压缩效果越好)
2. 测试已验证解压数据与原始文件完全一致
#第二次
================================================================================
压缩算法性能测试(10次取平均值)
测试文件:/Users/lilj/Desktop/work_python/day_1/mongodb_test_data.jsonl
================================================================================
原始文件大小:100.00 MB
正在运行第 1/10 次测试...
正在运行第 2/10 次测试...
正在运行第 3/10 次测试...
正在运行第 4/10 次测试...
正在运行第 5/10 次测试...
正在运行第 6/10 次测试...
正在运行第 7/10 次测试...
正在运行第 8/10 次测试...
正在运行第 9/10 次测试...
正在运行第 10/10 次测试...
================================================================================
最终测试结果(10次平均值)
================================================================================
算法 平均压缩耗时(ms) 平均解压耗时(ms) 压缩比 压缩后大小(MB)
---------------------------------------------------------------------------
Snappy 153.94 143.12 2.32 43.15
Zstd(l3) 270.58 77.32 3.55 28.16
zlib(l3) 1074.32 331.38 3.26 30.63
💡 说明:
1. 压缩比 = 原始大小 / 压缩后大小(数值越大压缩效果越好)
2. 测试已验证解压数据与原始文件完全一致测试结果
汇总数据(10 次平均)
| 算法 | 平均压缩耗时(ms) | 平均解压耗时(ms) | 压缩比 | 压缩后大小(MB) |
|---|---|---|---|---|
| Snappy | 199.22 | 139.54 | 2.32 | 43.15 |
| Zstd(l3) | 266.02 | 75.73 | 3.55 | 28.16 |
| zlib(l3) | 1030.00 | 304.97 | 3.26 | 30.63 |
存储节省对比
| 算法 | 100MB数据实际占用 | 节省空间 |
|---|---|---|
| 不压缩 | 100 MB | 0% |
| Snappy | 43.15 MB | 57% |
| Zstd | 28.16 MB | 72% |
| zlib | 30.63 MB | 69% |
性能影响
| 算法 | 写入延迟增加 | 影响程度 |
|---|---|---|
| Snappy | +199ms | 🟢 极小 |
| Zstd | +266ms | 🟡 可接受 |
| zlib | +1030ms | 🔴 严重 |
读取性能提升
| 算法 | 网络传输时间减少 | 解压时间增加 | 净收益 |
|---|---|---|---|
| Snappy | 57% | +140ms | 🟡 持平 |
| Zstd | 72% | +76ms | 🟢 正收益 |
| zlib | 69% | +305ms | 🔴 负收益 |
结果分析
✅ Zstd 是 MongoDB 文档场景的最优解
- 压缩率最高(3.55x)
- 解压速度最快(76ms,优于 Snappy)
- 压缩速度略慢于 Snappy,但在大多数业务可接受范围内
⚠️ Snappy 并非“过时”
- 在 高频写入 / 热集合 场景中,Snappy 仍是稳妥选择
- CPU 敏感型业务可优先考虑 Snappy
❌ zlib 性价比最低
- 压缩慢、解压慢、压缩率不如 Zstd
- 仅建议在 必须兼容 gzip 的老系统 中使用
线上部署
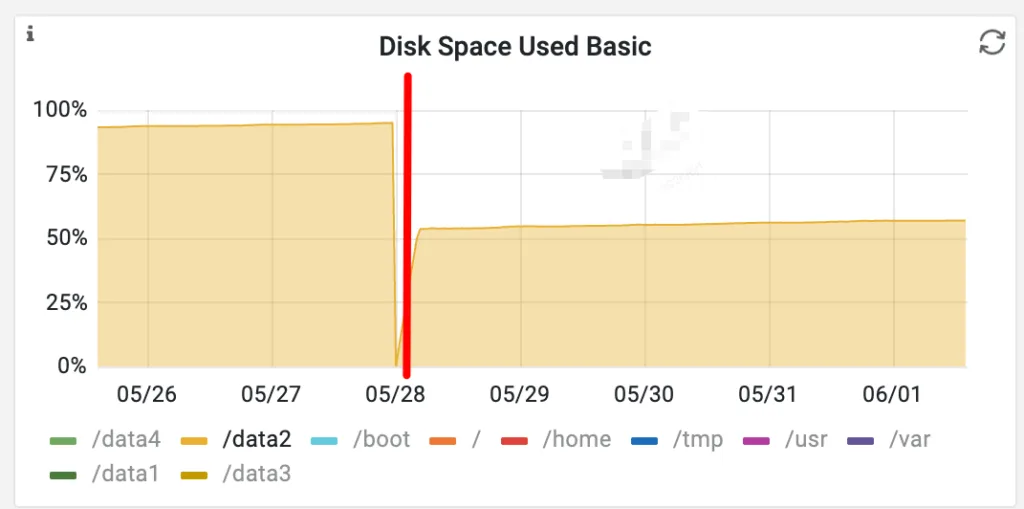
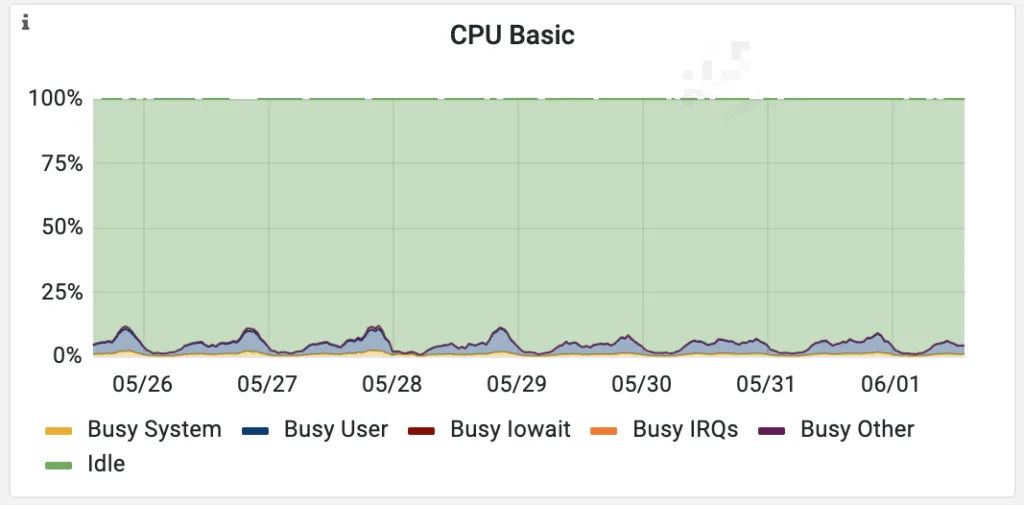
在一次生产集群扩容受限的场景中:
| 指标 | 切换前(snappy) | 切换后(zstd) |
|---|---|---|
| 磁盘使用率 | 95% | 55% |
| CPU 使用率 | 基线 | 无明显上升 |
| 写入延迟 | 基线 | 小幅增加(可接受) |
✅ 在不增加硬件成本的前提下,显著提升了存储上限。
写在最后
大家都在拼算力、拼集群、拼调度,但真正悄悄烧钱的,往往是“文件格式 + 压缩算法”这种底层细节。
文件格式 + 压缩算法,是隐形成本高地
在 MongoDB 文档场景下:
- Zstd level 3 在存储节省、解压性能、CPU 消耗之间取得最佳平衡
- 适合作为新业务的默认选择
生产变更前,建议在小流量集合验证,时刻监控磁盘、CPU、写入延迟。
在 MongoDB 文档场景下,Zstd 是存储成本与性能之间的最优解;Snappy 则是高频写入场景的安全选择。