
上传变慢根因排查与验证
事情背景
上周有一天工作日研发同学反馈某核心服务上传文件到分布式存储特别慢,排查后端的上传服务没有发现问题,怀疑是网络的问题。简单说一下我们的这个服务逻辑,用户上传文件–>接入负载均衡集群–>后端服务–>内网上传服务–>分布式存储,用户侧能感知并且可以复现上传慢的问题。
排查问题
网络上后端服务在A机房,内网上传服务在B机房,两个机房直接通过专线连接。先检查当天是否存在服务发布,确认服务侧没有发布版本;查看后端服务(部署在容器编排平台中)所在容器资源统计,未发现异常;
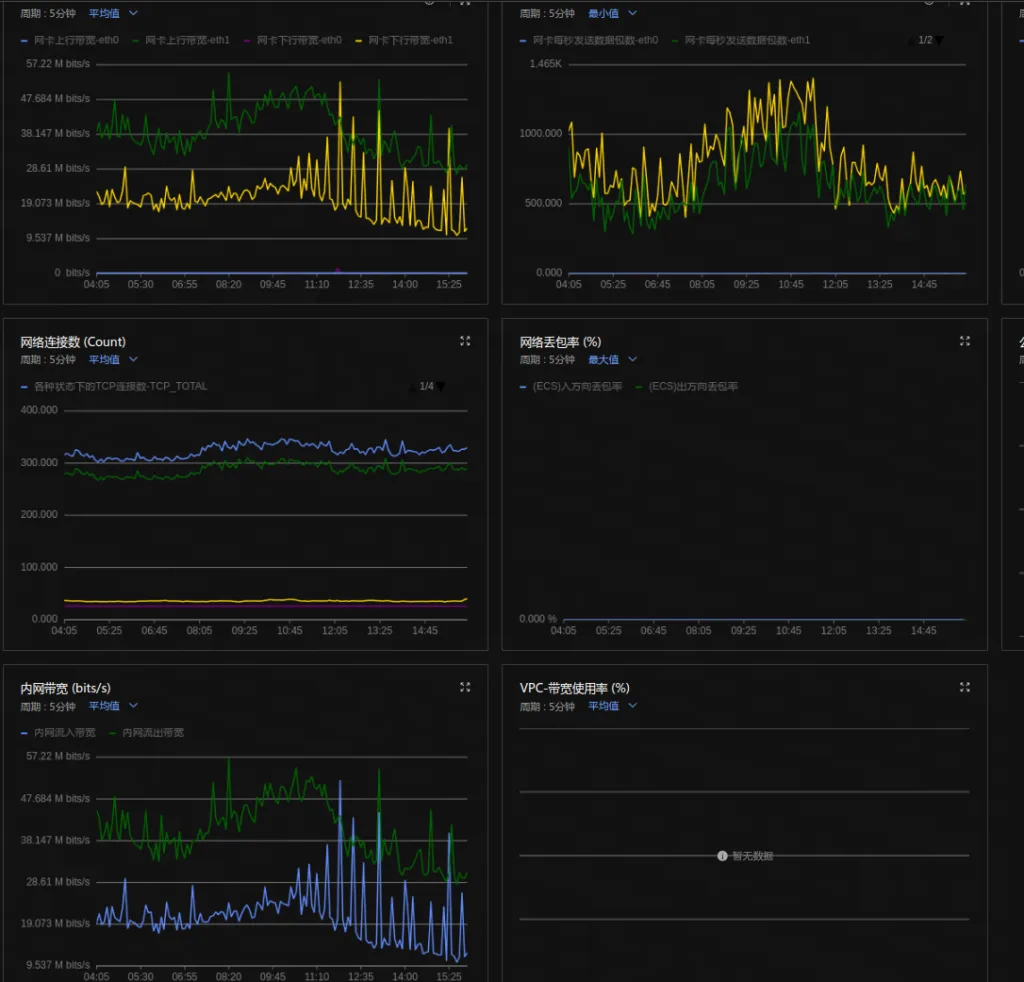
在A机房容器上使用 iperf3 -s去测试连接B机房机器网络情况,同时开启ping检测,网络传输稳定也没有发现异常;查询A机房到B机房直接的专线流量也没有特别大的波动。
发现在A机房部署的一个也涉及上传文件的服务也出现上传分布式存储延迟增加,延迟卡在报警阈值临界点,未触发监控报警。
研发同学提供一个curl 访问上传接口的测试脚本,将网络连接的各个阶段耗时打印出来,指定内网负载均衡 IP进行测试发现
-w "DNS解析: %{time_namelookup}s\nTCP连接: %{time_connect}s\nSSL握手: %{time_appconnect}s\n传输开始前: %{time_pretransfer}s\n首字节时间: %{time_starttransfer}s\n总时间: %{time_total}s\n"
DNS解析: 0.000023s
TCP连接: 0.031959s
SSL握手: 0.075002s
传输开始前: 0.075036s
首字节时间: 0.106913s
总时间: 2.425590s主要耗时在数据传输:总时间 2.426秒 中,有超过 2.3秒 花在了接收响应体上。这通常意味着与服务器之间的网络带宽有限,或者当时网络拥塞,导致传输速度慢。
查看上传服务的负载均衡集群接入机器的各种资源指标也没有发现异常,很奇怪。
快速解决
在各方面暂时查不出来的情况下需要快速修复上传慢的问题,降低用户不满。
有备用的内网负载均衡机器,先将上传域名内网解析改动备用负载均衡机器上,上传慢的问题一下就解决,然后技术团队观察服务,用户上传这块恢复到之前的延迟。
其他因素分析
曾怀疑与历史网络事件有关,但经确认时间不吻合。
在A机房A机器和B机房负载均衡B机器上进行tcpdump抓包分析,生成a.cap和b.cap,直接丢给AI大模型进行分析,AI大模型分析了抓包基本信息、TCP 握手与 RTT,从网络包中发现一些异常:服务端接收窗口急剧缩小,窗口瓶颈导致的吞吐量下降
| 跟踪服务端在每个 ACK 中通告的接收窗口变化(wscale=9,实际窗口 = win × 512): | |||
| 时间 | 服务端 win 值 | 实际窗口大小 | 说明 |
|---|---|---|---|
| 56.057 (SYN-ACK) | 21720 | ~10.6MB | 初始窗口,正常 |
| 56.090 | 43 | ~21KB | 第一批 ACK,骤降 |
| 56.156 | 36 | ~18KB | 持续收缩 |
| 56.157 | 25 → 17 → 12 | 6.1KB | 快速缩到底 |
| 56.158 ~ 59.225 | 持续 12 | 6.1KB | 整个传输过程卡在此值 |
| 结论:窗口从初始 ~10MB 在不到 100ms 内缩小到 6KB,之后再也没有恢复。 | |||
| 窗口瓶颈导致的吞吐量下降 | |
| 理论吞吐量 | 窗口 6,144 bytes / RTT 33ms ≈ 186 KB/s |
| 理论传输时间 | 586KB / 186 KB/s ≈ 3.15 秒(与实际 3.3 秒吻合) |
| 正常情况 | 窗口保持 41(~21KB)时:吞吐量 ≈ 636 KB/s → 586KB 仅需 ~0.92 秒 |
| 结论:传输耗时完全由服务端的小接收窗口决定。 | |
结合上传服务的Access日志
| 同时段 access log 中的上传请求: | ||||||
| 时间 | req_len | req_time | ups_resp_time | ups_conn_time | 计算速率 | 说明 |
|---|---|---|---|---|---|---|
| 15:55:50 | 112MB | 573s | 5.9s | 0.000s | ~196 KB/s | req_time(总耗时)高达数百秒,时间花在 负载均衡 接收客户端 body 阶段。 ups_resp_time 仅 ~6 秒,转发给 upstream 后处理很快。 负载均衡使用先收完 body 再转发。 瓶颈在”客户端→负载均衡”这一段,upstream 无问题。 |
| 15:55:57 | 53MB | 318s | 5.7s | 0.000s | ~167 KB/s | |
| 15:57:01 | 112MB | 574s | 6.1s | 0.000s | ~196 KB/s | |
查看TCP 滑动窗口对应的内核参数net.ipv4.tcp_mem 以及故障时候Prometheus拿到的node_sockstat_TCP_mem 指标统计
通过 Prometheus 查询 node_sockstat_TCP_mem 指标,对比三天数据: | |||
| 日期 | tcp_mem 最大值(页) | 距 pressure 阈值 | 状态 |
|---|---|---|---|
| 前一天 | 53,618 | 余量 38% | 正常 |
| 故障发生 | 85,371 | 仅差 2.3%(~8MB) | 异常 |
| 后一天 | 54,207 | 余量 38% | 恢复正常 |
| 4.14 峰值距阈值仅差 2,009 页(~8MB)。Prometheus 采样间隔 15 秒,实际瞬时峰值大概率已突破 87,380 触发 pressure。 | |||
net.ipv4.tcp_mem 的 pressure 阈值配置很小,故障时间中TCP 连接内存总量飙升至阈值附近(85,371 / 87,380),触发内核 pressure 模式,内核强制缩小所有 TCP 连接的接收窗口至最小值(6KB),导致上传吞吐量降至 ~186KB/s,使得上传文件延迟增大很多。
根因验证
第二天自动就恢复了,需要对是否是因为net.ipv4.tcp_mem 这个配置导致的进行根因验证,通过在负载均衡 服务器上主动构造 TCP memory pressure 场景,验证分析报告中”tcp_mem pressure 阈值过低导致接收窗口缩小、上传变慢”的根因结论。
Linux TCP内存管理机制
Linux 内核通过 net.ipv4.tcp_mem 参数控制所有 TCP 连接的全局内存使用,包含三个阈值(单位:内存页,每页 4KB): |
| 阈值 | 含义 |
| low | TCP 总内存低于此值时,内核不做任何干预 |
| pressure | TCP 总内存超过此值时,内核进入 pressure 模式,主动缩小所有连接的接收窗口以减少内存占用 |
| high | TCP 总内存超过此值时,内核拒绝分配新的 TCP 内存(极端情况) |
| Pressure 模式的影响: 1. 内核将 /proc/sys/net/ipv4/tcp_memory_pressure 标志位置为 12. 所有 TCP 连接的接收窗口被强制缩小 3. 缩小后的窗口限制 TCP 吞吐量: 吞吐量 = 窗口大小 / RTT4. 当内存回落到 low 以下时,pressure 解除,窗口恢复 |
tcp_mem 原理简述
参考:https://xiaolincoding.com/network/3_tcp/tcp_feature.html#%E6%BB%91%E5%8A%A8%E7%AA%97%E5%8F%A3
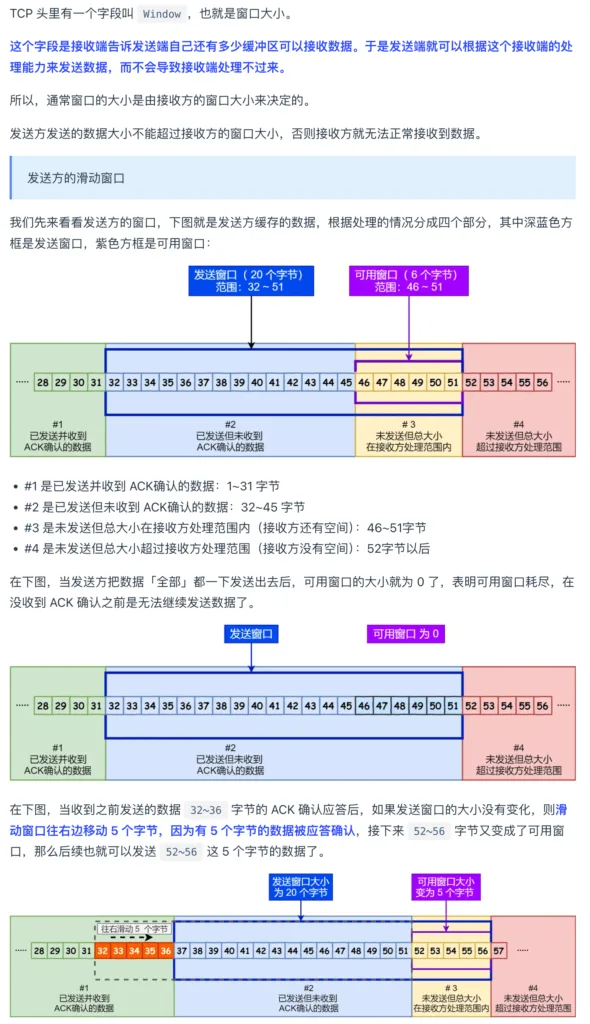
| TCP 的 Window(窗口)字段是接收方告诉发送方”我还能接收多少数据”的值。发送方在途数据量不能超过这个窗口,否则必须停下来等 ACK。因此: 窗口越大 → 发送方一次能发更多数据 → 管道利用率高 → 吞吐量高 窗口越小 → 发送方发一点就得等 ACK → 大量时间在等待 → 吞吐量低 net.ipv4.tcp_mem 管理的是整台机器所有 TCP 连接的内存总量(不是单个连接)。当总量超过 pressure 阈值时,内核为了回收内存,强制把所有连接的接收窗口缩到最小——不管这个连接是不是导致内存超标的那个。这就像一栋楼的总水压不够时,每家每户的水龙头出水都会变小。 |
验证方案设计
| 测试策略 | |
| 生产环境 pressure 阈值为 87,380 页(341MB),需要 11 万+连接才能触发,不便复现。 因此采用降低阈值的方法: 1. 将 tcp_mem 设置为极小值(pressure=2048 页=8MB),使 30 个连接即可填满2. 通过 Python 脚本精确控制 TCP 内存水位,维持在 pressure 附近 3. 同时从不同网络位置发起真实上传请求,对比 pressure 触发前后的速度变化 |
在测试Nginx将将 tcp_mem 设置为极小值,使少量连接即可触发 pressure:
sysctl -w net.ipv4.tcp_mem="1024 2048 4096"
sysctl -a| grep net.ipv4.tcp_mem
net.ipv4.tcp_mem = 1024 2048 4096启动 TCP 内存监控脚本,在 Nginx 服务器上运行,每秒采样一次 TCP 内存使用情况,与 pressure 阈值对比。
#!/bin/bash
# 文件: watch_tcp.sh
# 功能: 每秒监控 TCP 全局内存使用量,与 pressure 阈值对比
read LOW PRES HIGH < <(sysctl -n net.ipv4.tcp_mem)
echo "tcp_mem: low=LOW页pressure= {PRES}页 high=${HIGH}页"
echo "换算: low=((LOW41024))MBpressure=(( PRES*4/1024 ))MB high=$(( HIGH*4/1024 ))MB"
echo ""
printf "%-12s %-10s %-10s %-10s %-10s %-20s\n" \
"时刻" "内存(页)" "内存(MB)" "阈值(MB)" "使用率%" "状态"
echo "----------------------------------------------------------------------"
while true; do
TS=$(date +"%H:%M:%S")
MEM_PAGES=Missing close braceNF}' /proc/net/sockstat)
MEM_MB=(echo"scale=2; {MEM_PAGES} * 4 / 1024" | bc)
PCT=(echo"scale=1; {MEM_PAGES} * 100 / ${PRES}" | bc)
PCT_INT=(echo" {MEM_PAGES} * 100 / ${PRES}" | bc)
if [ "${PCT_INT}" -gt 100 ]; then STATUS="[!!] 超过pressure阈值"
elif [ "${PCT_INT}" -gt 95 ]; then STATUS="[!] 接近上限"
elif [ "${PCT_INT}" -gt 85 ]; then STATUS="[*] 目标区间"
elif [ "${PCT_INT}" -gt 50 ]; then STATUS="[-] 偏低"
else STATUS="[OK] 正常"
fi
printf "%-12s %-10s %-10s %-10s %-10s %-20s\n" \
"TS"" {MEM_PAGES}页" "${MEM_MB}MB" \
"((PRES41024))MB"" {PCT}%" "${STATUS}"
sleep 1
done
脚本原理:
- 从 /proc/net/sockstat 读取 TCP: ... mem 字段,获取当前 TCP 全局内存页数
- 与 sysctl net.ipv4.tcp_mem 的 pressure 阈值对比,计算使用率百分比
- 状态分级:正常 → 偏低 → 目标区间 → 接近上限 → 超过阈值启动 TCP Memory Pressure 构造脚本
#!/usr/bin/env python3
"""TCP Memory Pressure 实验 - 限速读取版"""
import socket, threading, time, os, re, sys, select, datetime
# -- 配置 --
SERVER_HOST = "127.0.0.1"
SERVER_PORT = 80
NUM_CONNECTIONS = 30 # 创建 30 个 TCP 连接
SEND_CHUNK = 65536 # 客户端每次发 64KB
MONITOR_INTERVAL = 1 # 监控输出间隔 1 秒
HOLD_DURATION = 120 # 实验持续 120 秒
TARGET_LOW_PCT = 88.0 # 低于此值:停止读取(让内存堆积)
TARGET_HIGH_PCT = 95.0 # 高于此值:开始读取(释放内存)
RECV_CHUNK = 4096 # 每次只读 4KB(控制释放速度)
RECV_INTERVAL = 0.05 # 每轮读取后暂停 50ms
stop_event = threading.Event()
do_recv = threading.Event() # True=读取释放内存, False=不读取堆积内存
do_recv.clear()
def get_tcp_stats():
"""从 /proc 读取 TCP 内存使用情况和 pressure 状态"""
try:
mem_pages = 0
with open("/proc/net/sockstat") as f:
for line in f:
if line.startswith("TCP:"):
m = re.search(r'\bmem\s+(\d+)', line)
if m: mem_pages = int(m.group(1))
break
with open("/proc/sys/net/ipv4/tcp_mem") as f:
parts = f.read().strip().split()
low, pres, high = int(parts[0]), int(parts[1]), int(parts[2])
p_file = "/proc/sys/net/ipv4/tcp_memory_pressure"
if os.path.exists(p_file):
with open(p_file) as f: pressure = int(f.read().strip())
else:
pressure = 1 if mem_pages > pres else 0
return {
"mem_pages": mem_pages, "mem_mb": mem_pages * 4 / 1024,
"pressure": pressure, "pres_pages": pres,
"pressure_mb": pres * 4 / 1024,
"usage_pct": mem_pages / pres * 100 if pres > 0 else 0,
}
except Exception as e:
return {"error": str(e)}
def memory_controller():
"""
内存控制器 - 双阈值滞回(hysteresis)控制
每 0.1 秒采样:
> 95% -> 开启读取(释放内存)
< 88% -> 关闭读取(堆积内存)
中间 -> 维持当前状态(防抖)
"""
state = "fill"
while not stop_event.is_set():
s = get_tcp_stats()
if "error" in s: time.sleep(0.1); continue
pct = s["usage_pct"]
if pct > TARGET_HIGH_PCT and state != "drain":
do_recv.set(); state = "drain"
elif pct < TARGET_LOW_PCT and state != "fill":
do_recv.clear(); state = "fill"
time.sleep(0.1)
def server_thread(port):
"""
服务端线程 - 限速读取
关键机制:
1. RECV_CHUNK=4KB - 每次释放少量内存
2. 每轮 sleep 50ms - 控制释放速率
3. do_recv=False 时完全不读 - 数据堆积在内核 TCP 接收缓冲区
"""
srv = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
srv.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
srv.bind((SERVER_HOST, port)); srv.listen(500); srv.setblocking(False)
conn_list = [srv]
while not stop_event.is_set():
try: readable, _, _ = select.select(conn_list, [], [], 0.2)
except: break
for sock in readable:
if sock is srv:
try:
conn, _ = srv.accept(); conn.setblocking(False)
conn.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF, 256*1024)
conn_list.append(conn)
except: pass
else:
if do_recv.is_set():
try:
data = sock.recv(RECV_CHUNK)
if not data: conn_list.remove(sock); sock.close()
except BlockingIOError: pass
except: conn_list.remove(sock); sock.close()
if do_recv.is_set() and len(readable) > 1: time.sleep(RECV_INTERVAL)
for s in conn_list:
try: s.close()
except: pass
def client_sender(conn_id, port):
"""客户端线程 - 持续发送 64KB 数据块"""
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF, 4*1024*1024)
try:
sock.connect((SERVER_HOST, port)); sock.setblocking(False)
data = b'X' * SEND_CHUNK
while not stop_event.is_set():
try: sock.send(data)
except BlockingIOError: time.sleep(0.05)
except OSError: break
except: pass
finally:
while not stop_event.is_set(): time.sleep(1)
try: sock.close()
except: pass
def main():
stats = get_tcp_stats()
port = find_free_port(29999)
# 启动 server, controller, monitor 线程
threading.Thread(target=server_thread, args=(port,), daemon=True).start()
time.sleep(0.3)
threading.Thread(target=memory_controller, daemon=True).start()
threading.Thread(target=monitor_loop, daemon=True).start()
# 逐批创建 30 个客户端连接(每批 5 个)
for i in range(NUM_CONNECTIONS):
threading.Thread(target=client_sender, args=(i, port), daemon=True).start()
if (i+1) % 5 == 0: time.sleep(0.2)
try: time.sleep(HOLD_DURATION)
except KeyboardInterrupt: pass
stop_event.set(); time.sleep(3)| 脚本核心原理:双阈值滞回控制 | |
| 30 个客户端线程 | 每个线程建立一个 TCP 连接,持续向服务端发送 64KB 数据块 |
| 服务端线程 | 使用 select 多路复用管理所有连接,根据 do_recv 标志决定是否读取数据 |
| 内存控制器 | 每 0.1 秒采样 TCP 内存,使用滞回控制: 内存 > 95% 时:开启小口读取(每次 4KB,间隔 50ms)释放内存 内存 < 88% 时:停止读取,让内存重新堆积 |
| 监控线程 | 每秒输出内存页数、MB、使用率百分比、pressure 标志状态 |
这个脚本的核心目的是:在本地制造大量"发了但没人读"的 TCP 数据,让内核的 TCP 内存堆积超过 pressure 阈值。
整体架构
同一台 Nginx 服务器上(127.0.0.1)
┌─────────────────┐ ┌─────────────────┐
│ 客户端线程 x30 │ ──────→ │ 服务端线程 │
│ │ TCP │ │
│ 拼命发 64KB 数据 │ ──────→ │ 故意不读/慢读 │
│ │ TCP │ │
│ 数据堆在发送缓冲区│ ──────→ │ 数据堆在接收缓冲区│
└─────────────────┘ └─────────────────┘
│
数据没人读,堆在内核 TCP 缓冲区
│
▼
/proc/net/sockstat 的 TCP mem 飙升
│
▼
超过 tcp_mem 的 pressure 阈值(2048页=8MB)
│
▼
内核触发 TCP memory pressure!
强制缩小所有连接(包括外部 curl)的接收窗口
为什么数据会堆积?
TCP 是有缓冲区的:
客户端 send() 服务端 recv()
│ │
▼ ▼
┌──────────┐ 网络 ┌──────────┐ ┌──────────┐
│ 发送缓冲区 │ ────────→ │ 接收缓冲区 │ → │ 应用层读取 │
│ (内核管理) │ │ (内核管理) │ │ │
└──────────┘ └──────────┘ └──────────┘
│
服务端不调用 recv()
→ 数据一直堆在这里
→ 占用内核 TCP 内存
- 客户端不停 send(),数据进入内核的发送缓冲区,再通过 TCP 传到对端
- 服务端故意不调用 recv(),数据就堆在内核的接收缓冲区里
- 30 个连接同时堆积,TCP 全局内存快速上涨
四个线程角色
1. 客户端线程(30个)—— 只管往里灌数据
def client_sender(conn_id, port):
sock.connect((SERVER_HOST, port)) # 连到本地服务端
data = b'X' * 65536 # 准备 64KB 垃圾数据
while not stop_event.is_set():
sock.send(data) # 死循环不停发
作用:持续产生 TCP 数据流,让内核缓冲区不断填充。
2. 服务端线程(1个)—— 控制"读不读"
def server_thread(port):
# 接受所有连接,但是:
for sock in readable:
if do_recv.is_set(): # 控制器说"读"
sock.recv(4096) # 每次只读 4KB(慢慢释放)
# else: # 控制器说"别读"
# 什么都不做 # 数据继续堆积!
关键:do_recv 这个开关决定服务端读不读数据。
- 不读 → 数据堆在内核接收缓冲区 → TCP 内存上涨
- 读 → 数据被应用层消费 → 内核释放缓冲区 → TCP 内存下降
- 每次只读 4KB + 间隔 50ms → 确保内存缓慢下降,不会一下子降太多
3. 内存控制器(1个)—— 自动调节水位
def memory_controller():
while True:
pct = 当前TCP内存 / pressure阈值 * 100
if pct > 95%: # 太高了,快爆了
do_recv.set() # 告诉服务端:开始读,释放一些内存
elif pct < 88%: # 降得够低了
do_recv.clear() # 告诉服务端:停止读,让内存重新堆上来
# 88%~95% 之间:维持现状,不动
这是一个双阈值滞回控制器,让 TCP 内存始终维持在 pressure 阈值附近:
TCP 内存
使用率%
100% ┄┄┄┄┄┄┄┄┄┄┄ pressure 阈值(2048页)
95% ──────────── 超过这里 → 开始读(内存下降)
╱╲ ╱╲
╱ ╲╱ ╲ ← 内存在这个区间震荡
88% ──────────── 低于这里 → 停止读(内存上涨)
4. 监控线程(1个)—— 每秒打印状态
def monitor_loop():
while True:
# 读 /proc/net/sockstat 获取 TCP 内存页数
# 读 /proc/sys/net/ipv4/tcp_memory_pressure 获取 pressure 标志
# 打印:时间 | 内存页数 | MB | 使用率% | 是否在读 | 状态
sleep(1)
纯展示,不影响逻辑。
为什么能影响外部 curl 上传?
这是最关键的一点:tcp_mem 是全局的,不是按连接的。
内核 TCP 内存池(全局共享)
┌──────────────────────────────────────────────┐
│ │
│ 脚本的 30 个连接 外部 curl 上传连接 │
│ 占了 2800 页 占了 30 页 │
│ │
│ 总计 = 2830 页 > pressure 阈值 2048 页 │
│ │
│ 内核:所有连接都缩小接收窗口! │
│ ↓ ↓ │
│ 脚本连接受影响 curl 连接也受影响! │
│ (无所谓) (上传变慢!) │
└──────────────────────────────────────────────┘
脚本的 30 个本地连接把 TCP 内存池吃满,内核不区分"谁的连接",一刀切缩小所有连接的窗口,包括同一时刻外部杭州/贵州 curl
发起的上传连接。这就是为什么 curl 上传会变慢。
一句话总结
脚本在本地造了 30 个"只发不收"的 TCP 连接来占满内核的 TCP 内存池,迫使内核进入 pressure 模式,从而影响到同一台机器上所有 TCP
连接(包括外部用户的上传请求)的接收窗口大小。测试执行与数据
监控脚本输出,基线和pressure触发阶段的输出如下所示:
tcp_mem: low=1024页 pressure=2048页 high=4096页
换算: low=4MB pressure=8MB high=16MB
时刻 内存(页) 内存(MB) 阈值(MB) 使用率% 状态
----------------------------------------------------------------------
15:01:15 22页 .08MB 8MB 1.0% [OK] 正常
15:01:16 21页 .08MB 8MB 1.0% [OK] 正常
15:01:17 21页 .08MB 8MB 1.0% [OK] 正常
15:01:18 27页 .10MB 8MB 1.3% [OK] 正常
15:02:37 2925页 11.42MB 8MB 142.8% [!!] 超过pressure阈值 <-- 突变!
15:02:38 3205页 12.51MB 8MB 156.4% [!!] 超过pressure阈值
15:02:39 3203页 12.51MB 8MB 156.3% [!!] 超过pressure阈值
15:02:40 3162页 12.35MB 8MB 154.3% [!!] 超过pressure阈值
15:02:41 3059页 11.94MB 8MB 149.3% [!!] 超过pressure阈值
15:02:42 3151页 12.30MB 8MB 153.8% [!!] 超过pressure阈值
15:02:43 2927页 11.43MB 8MB 142.9% [!!] 超过pressure阈值TCP Memory Pressure 构造脚本的输入如下:
=================================================================
TCP Memory Pressure 实验(限速读取版)
目标:维持在 88%~95%
=================================================================
初始状态:
TCP内存: 21 页 = 0.08MB
pressure阈值: 2048 页 = 8.00MB
目标区间: 7.04MB ~ 7.60MB
使用端口: 29999
连接数: 30
保持时长: 120秒
[Server] 监听端口 29999
开始创建连接(每批 5 个,共 30 个)...
==================================================================================
目标区间: 88% ~ 95% recv粒度: 4096B recv间隔: 50ms
==================================================================================
时刻 内存(页) 内存(MB) 阈值(MB) 使用率% 服务端 状态
==================================================================================
已创建 5/30 个连接
15:02:36 234 0.91 8.00 11.4% [STOP] [OK] 偏低,堆积中
已创建 10/30 ~ 25/30 个连接
15:02:37 2926 11.43 8.00 142.9% [READ] [!!] 超上限
--- !! Pressure 触发 ---
已创建 30/30 个连接
连接创建完毕,自动维持目标区间...
15:02:38 3209 12.54 8.00 156.7% [READ] [!!] 超上限
15:02:39 3202 12.51 8.00 156.3% [READ] [!!] 超上限
15:02:40 3165 12.36 8.00 154.5% [READ] [!!] 超上限使用curl进行上传测试,统计TCP连接耗时、首字节时间和总时间,同时获取测试Nginx机器的node_sockstat_TCP_mem数据进行交叉验证
pressure 阈值 = 2048 页 = 8MB(测试期间设置的低阈值),基线正常值 = 29~42 页 (0.11~0.16MB)
| 时间 | TCP内存(页) | 换算MB | 占阈值% | 状态 |
| 15:03:00 | 2815 | 11.00 | 137% | 超过阈值 – 正式测试(文档记录) |
| 15:03:30 | 2529 | 9.88 | 123% | 超过阈值 |
Prometheus 15 秒采样间隔捕获到 TCP 内存尖峰
| 轮次 | 时间段 | Prometheus采样峰值 | 占pressure阈值 | 说明 |
| 正式测试 | 15:03:00 ~ 15:03:45 | 2815 页 (11.00MB) | 137% | 文档记录的正式测试 |
结论与监控改进
正式测试阶段(15:02:37 ~ 15:03:45),Prometheus 采样数据与 TCP 内存监控脚本本地监控数据对齐,形成双重互证。
验证的因果链条:
tcp_mem 的 pressure 阈值过低(生产 341MB / 测试 8MB)
↓
TCP 连接总内存超过 pressure 阈值
↓
内核进入 TCP memory pressure 模式(tcp_memory_pressure = 1)
↓
内核强制缩小所有 TCP 连接的接收窗口
↓
上传吞吐量按 “窗口/RTT” 公式下降(RTT 越高影响越大)
↓
Pressure 解除后,窗口恢复,上传速度恢复正常
后期需要增加监控 node_sockstat_TCP_mem 接近 pressure 阈值时告警(建议 80% 阈值),检查其他负载均衡机器的 sysctl net.ipv4.tcp_mem,确认是否存在同样的误配置。
写在最后
有了AI的加持可以对一些网络问题进行快速分析和给出修复建议,有句古话“祸患常积于忽微”,对一些线上问题需要反复推敲验证,找出根因而不浮于表面。