
初探Percona MongoDB增量备份
前言

最近在学习MongoDB相关知识,MongoDB集群数据小的时候可以通过自带的备份命令来处理,命令如下:
| 特性维度 | mongodump & mongorestore | mongoexport & mongoimport |
|---|---|---|
| 数据处理格式 | BSON (MongoDB 的二进制格式) | JSON 或 CSV (文本格式) |
| 速度与体积 | ⭐️⭐️⭐️⭐️⭐️ (二进制,速度快,体积小) | ⭐️⭐️⭐️ (文本格式,速度相对慢,体积较大) |
| 元数据保留 | 保留索引、集合属性等元数据信息 | 不保留索引、账户信息等元数据 |
| 版本兼容性 | 对 MongoDB 版本敏感,不同版本间可能不兼容 | 版本兼容性好,适合跨大版本或异构平台迁移 |
| 适用场景 | 同版本或兼容版本的日常备份与恢复、全量迁移 | 选择性数据迁移、跨平台数据交换、数据导出分析 |
| 数据类型支持 | 支持所有 BSON 数据类型,兼容性最好 | 某些 BSON 特殊类型在 JSON/CSV 中可能无法完美表示 |
企业使用的最多的还是副本集群,副本集群一般通过全量备份+Oplog来实现,但是这里有一个问题,副本集群数据量如果有几T,全量备份的时间超过Oplog时间,备份节点再使用Oplog已经无法追上主节点数据。
这种场景下需要研究一下增量备份的方案,了解到percona这家厂商家有https://docs.percona.com/percona-backup-mongodb/features/backup-types.html
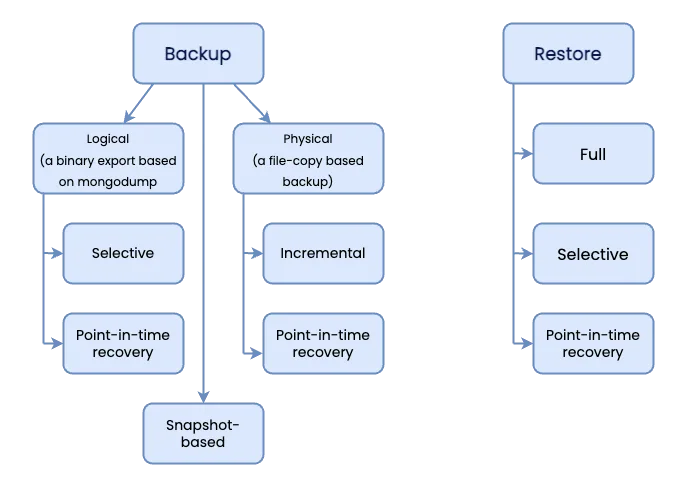
| 特性 | 逻辑备份(Logical) | 物理备份(Physical) |
| 备份原理 | 使用 mongodump 导出数据 | 直接复制数据文件(如 WiredTiger 存储引擎文件) |
| 兼容性 | ⭐ 极高(支持所有 MongoDB 版本) | ⚠️ 仅限 Percona Server for MongoDB ≥4.2.24 / 5.0.14 / 6.0.3 |
| 性能与速度 | 较慢(需遍历文档) | ⭐ 极快(接近文件拷贝) |
| 资源占用 | 高 CPU、内存(解析 BSON) | 低 CPU,但高磁盘 IO |
| 备份大小 | 可压缩好(尤其用 s2/gzip) | 更小(原生二进制格式) |
| 恢复方式 | 使用 mongorestore 导入 | 快速替换数据目录后重启 |
| 是否支持 PITR | ✅ 支持(结合 oplog) | ✅ 支持(更高效) |
| 跨版本恢复能力 | ✅ 强(适合迁移升级) | ❌ 弱(必须相同或兼容版本) |
| 能否部分恢复集合? | ✅ 可以只恢复某个库/集合 | ❌ 不行,只能全实例恢复 |
| 是否依赖 mongodump? | ✅ 是 | ❌ 否 |
PBM测试
1.部署测试集群
| 副本集群 | th100\th101\th102 |
| 还原集群 | th103 |
#副本集群初始化
var cfg = {
_id: "lilj_test",
members: [
{_id: 0, host: "th100:30017"},
{_id: 1, host: "th101:30017"},
{_id: 2, host: "th102:30017"}
]
}
rs.reconfig(cfg, {force: true});
rs.status()
#还原节点初始化
rs.initiate({
_id: "lilj_test",
version: 1,
members: [
{ _id: 0, host: "localhost:30017" }
]
})2.部署PBM
创建备份用户和赋予库操作权限,参考percona官方文档创建备份用户
打算往minio上写入备份文件,PMB的配置格式如下
storage:
type: minio
minio:
region: ""
endpoint: minio URL地址
bucket: test-lilj
prefix: pbm/backup
credentials:
access-key-id: '***'
secret-access-key: '***'
secure: false
partSize: 10485760
retryer:
numMaxRetries: 10
insecureSkipTLSVerify: false#声明PBM_MONGODB_URI变量
export PBM_MONGODB_URI="mongodb://pbmuser:密码@127.0.0.1:30017/?authSource=admin"
#查看pbm状态,全部OK就可以了
./pbm status
Cluster:
========
lilj_test:
- th100:30017 [S]: pbm-agent [v2.12.0] OK
- th101:30017 [P]: pbm-agent [v2.12.0] OK
- th102:30017 [S]: pbm-agent [v2.12.0] OK
PITR incremental backup:
========================
Status [OFF]
#启动agent
./pbm-agent -f pbm_config.yaml > pbm-agent.log 2>&1 &
#查看状态
./pbm status
#测试连接s3
./pbm-speed-test storage
Test started ................
1.00GB sent in 34s.
Avg upload rate = 30.20MB/s.正常启动如果无法看到数据的话需要重新同步一下,具体命令如下所示:
./pbm config --file pbm_config.yaml --force-resync3.增量备份
1、MongoDB集群初始状态下test下面只有orders和products两个表
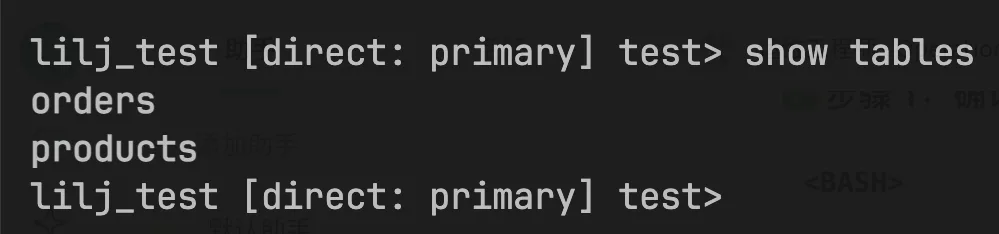
2、先进行一次完全备份,执行下面的命令:
./pbm backup --type incremental --base
在副本集群运行pbm命令,会随机在一个节点启动备份进场,在th102 备份进程开启并上传数据,如日志所示:
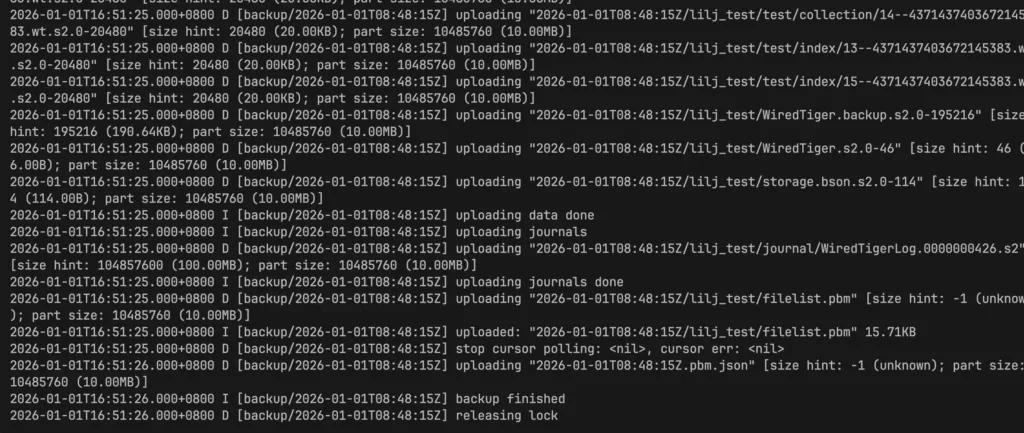
在minio上可以看到提交的文件

使用阿里云千问模型分析日志,梳理流程图和关键环节
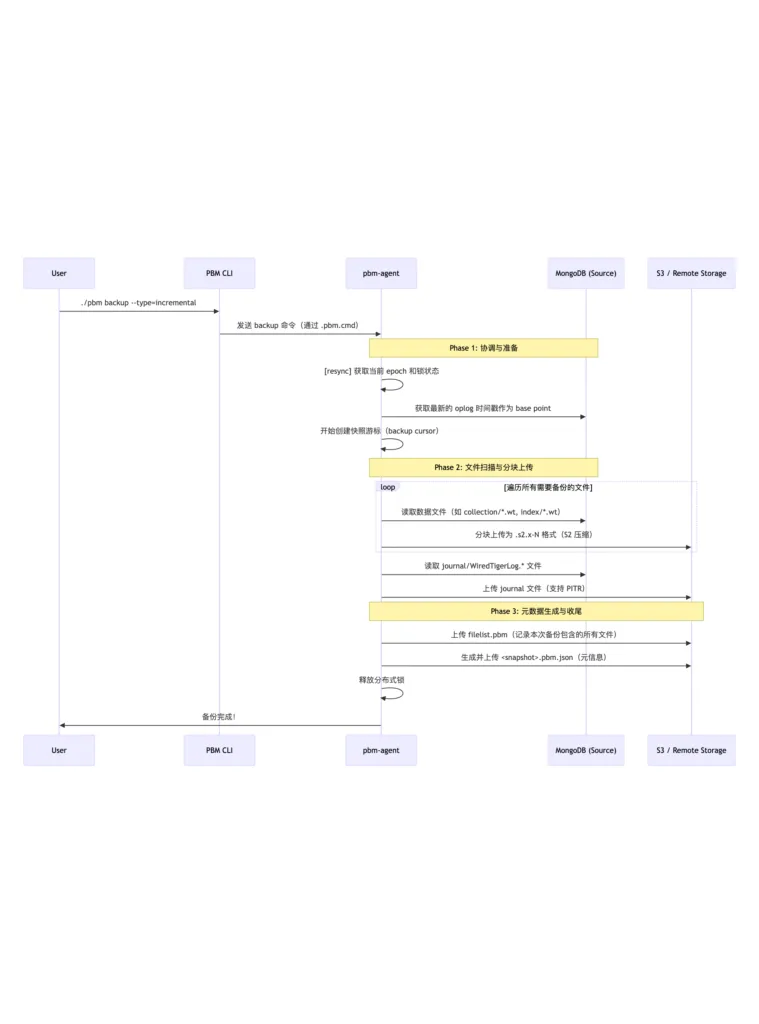
关键环节详细拆解(按时间线)
| 时间戳 | 日志片段 | 阶段 | 功能说明 |
| 16:47:03 | got command resync | 心跳同步 | Agent 定期轮询命令通道,获取最新备份/恢复指令 |
| 16:47:03 | [resync] lock not acquired | 锁检查 | 当前无冲突操作,可以继续下一步 |
| 16:47:36 | got command delete | 删除请求 | 用户可能尝试删除某个旧备份 |
| 16:47:36 | [delete] skip: lock not acquired | 跳过删除 | 因为正在执行其他任务或锁未就绪,暂不处理 |
| 16:48:15 | got command backup […] | 接收备份命令 | 收到用户发起的增量备份请求 |
| 16:48:16 | flush incremental backup history | 清理历史 | 确保增量链干净(避免断链) |
| 16:48:16 | backup cursor id: … | 创建快照点 | MongoDB 内部建立一个一致性的读视图(类似 snapshot) |
| 16:48:18 | set journal up to {…} | 设置日志起点 | 记录此次备份对应的 oplog 截止点,用于后续 PITR |
| 16:48:18 → 16:51:25 | uploading “*.s2.0-*” | 并行上传数据 | 将所有 WT 文件以 S2 压缩格式上传至远程存储 |
| 16:51:25 | uploading journals | 上传日志 | 上传最新的 WiredTigerLog.* 文件,保障可恢复性 |
| 16:51:25 | uploaded: filelist.pbm | 生成文件清单 | 列出本此备份涉及的所有文件路径 |
| 16:51:26 | backup finished | 成功结束 | 更新状态、释放锁、退出 |
第二步,删除orders表
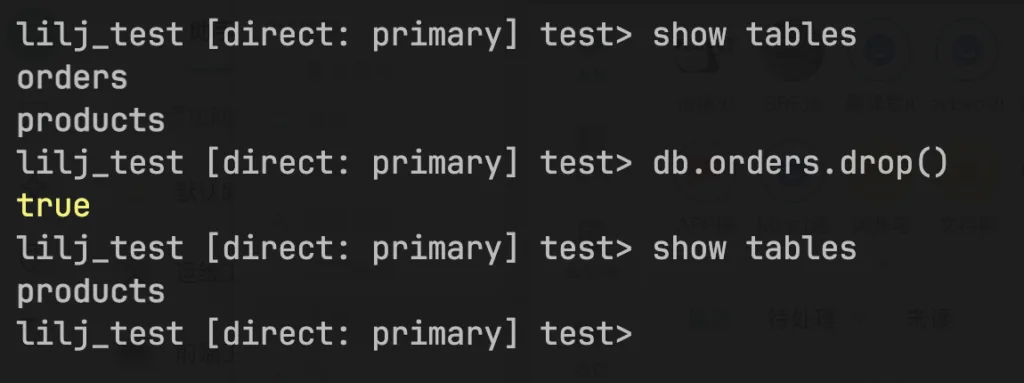
进行增量备份,操作命令如下:
./pbm backup --type incremental
pbm agentlog和minio信息如下:
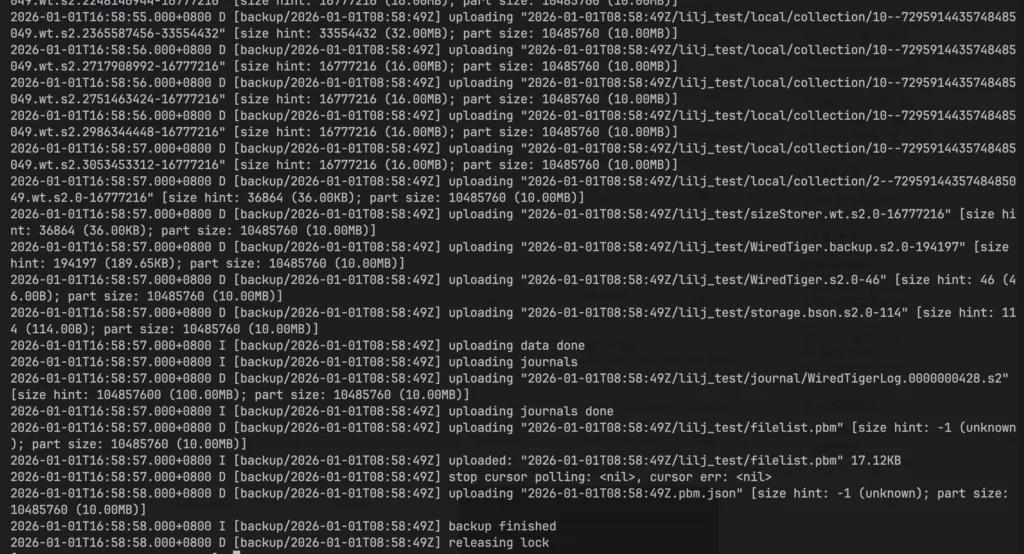
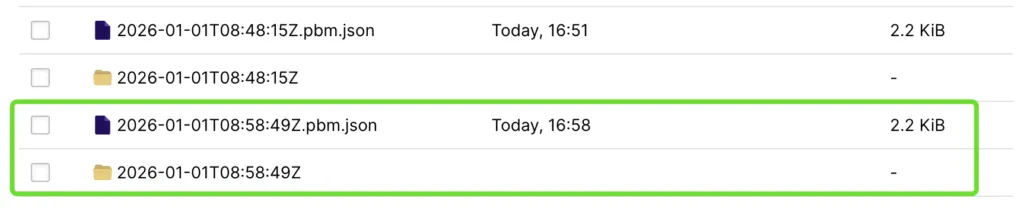
使用阿里云千问模型分析日志,梳理流程图和关键环节
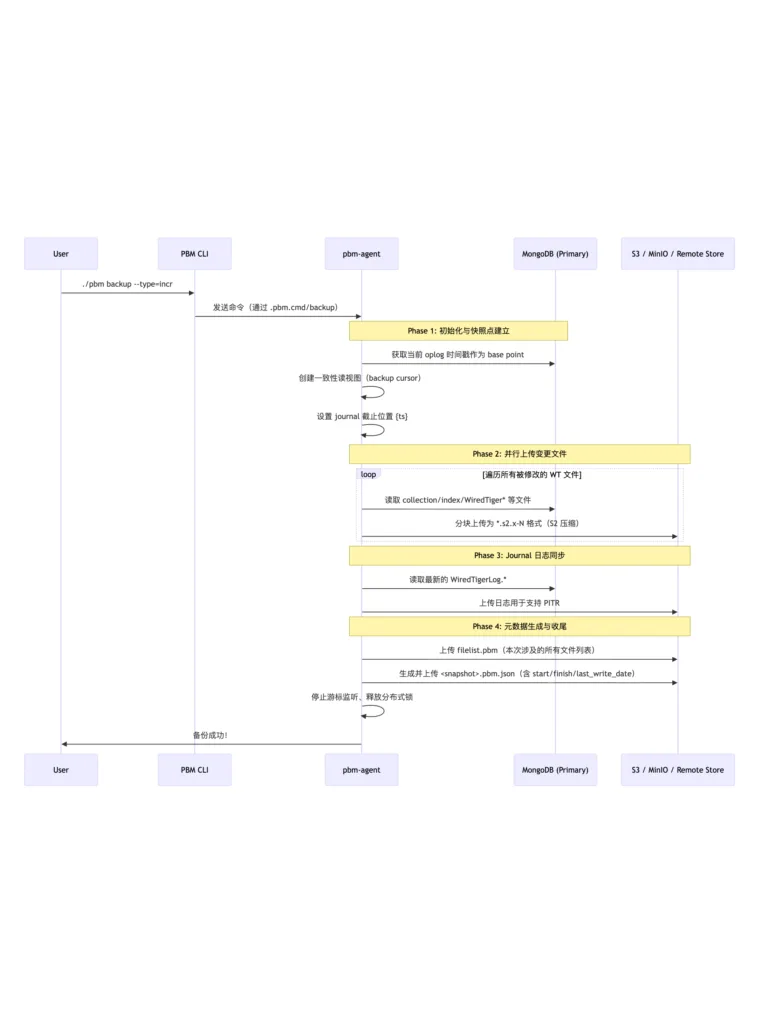
关键环节详细拆解(按时间线)
| 时间戳 | 日志片段 | 阶段 | 功能说明 |
| 16:58:50 | got command backup […] | 接收指令 | 用户或定时任务触发了新的增量备份 |
| 16:58:50 | [backup] backup started | 启动任务 | Agent 开始处理该次备份请求 |
| 16:58:51 | backup cursor id: … | 快照创建 | MongoDB 内部建立一个一致性的“读快照”视图,防止备份过程中数据抖动 |
| 16:58:53 | set journal up to {1767257931 4} | Oplog 锚定 | 记录此次备份对应的最后一个 oplog 时间戳,用于后续 PITR 定位起点 |
| 16:58:53 → 16:58:57 | uploading “*.s2.0-*” | 数据上传 | 将发生变化的 .wt 文件以 S2 压缩格式分片上传至远程存储 |
| 16:58:57 | uploading journals | Journal 上传 | 上传最新的事务日志(WiredTigerLog),保障可做时间点恢复 |
| 16:58:57 | uploaded filelist.pbm | 清单生成 | 生成文件清单,记录本次备份包含哪些文件及其大小 |
| 16:58:58 | uploading .pbm.json | 元数据写入 | 写入 JSON 描述符:时间、类型、节点、last_write_date、压缩方式等 |
| 16:58:58 | backup finished | 成功退出 | 整个流程顺利完成 |
| 16:58:58 | releasing lock | 锁释放 | 释放全局备份锁,允许下一次操作进入 |
4.恢复测试
th103准备一个单独实例的副本集群,运行pbm list 可以看到在minio上存储的备份数据列表:

#进行恢复第一次全量备份测试
./pbm restore 2026-01-01T08:48:15Z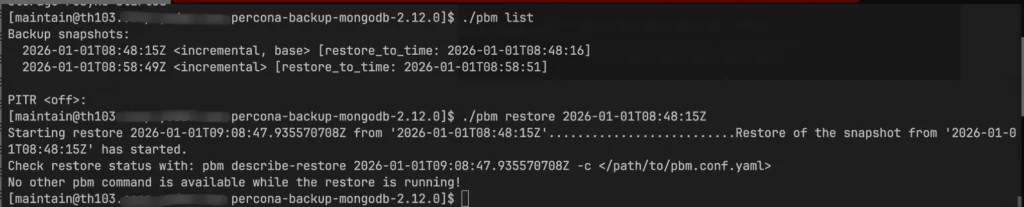
pbm-agent.log 日志如下
还原完成后MongoDB进程和 pbm-agent进程都退出,需要启动MongoDB进程。
使用阿里云千问模型分析日志,梳理流程图和关键环节
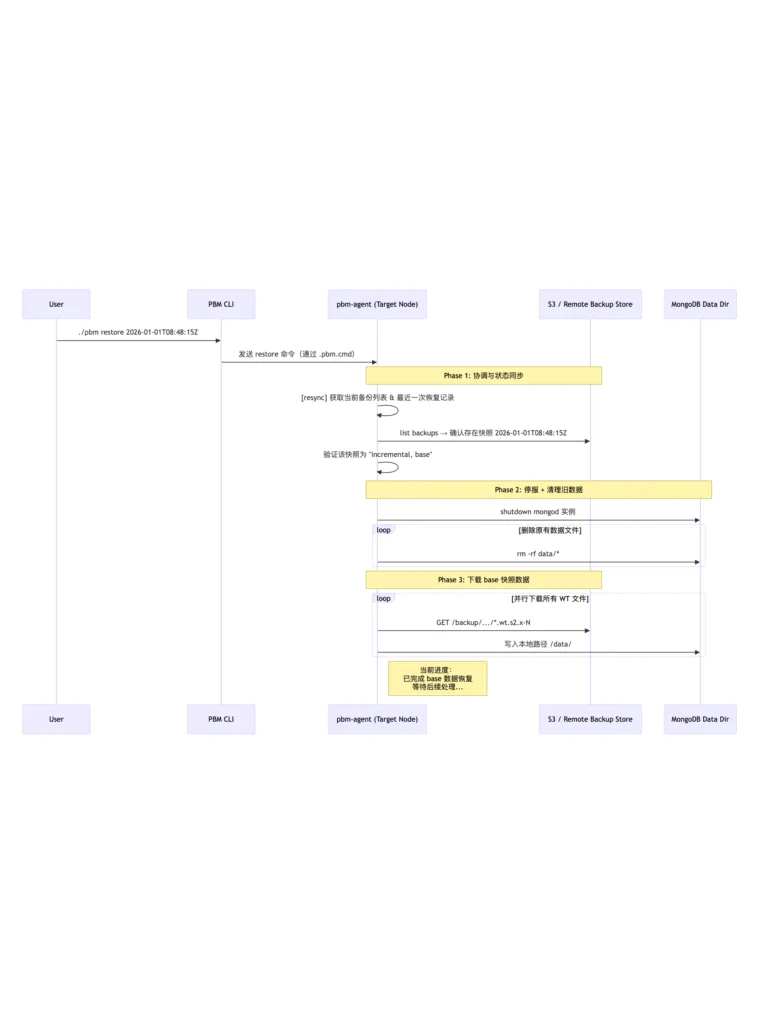
关键环节详细拆解(按时间线)
| 时间戳 | 日志片段 | 阶段 | 功能说明 |
| 17:04:12 | got command resync | 心跳协调 | Agent 定期检查命令通道,同步集群状态 |
| 17:04:12 | got backups list: 2 bcp: 2026-01-01T08:48:15Z, 08:58:49Z | 备份发现 | 发现两个增量快照,确认 08:48:15Z 是当前可恢复的 base |
| 17:08:48 | got command restore […] snapshot: 2026-01-01T08:48:15Z | 接收指令 | 用户发起恢复请求,指定 base 快照 |
| 17:08:48 | moving to state starting | 状态广播 | 创建 .starting 标志文件,通知其他组件准备开始 |
| 17:09:18 | stopping mongod and flushing old data | 停止服务 | 安全关闭目标 mongod 进程 |
| 17:09:20 | remove /disk0/mongodb_test/… | 清理数据 | 删除原 data 目录下所有文件(除 log 外) |
| 17:09:20 | copy <…> 开始 | 数据恢复 | 从远程存储下载 base 快照中的所有 .wt 文件、journal、WiredTiger 元文件 |
| 17:09:21 → 17:09:54 | copy dictpen_server/collection/32–*.wt → 45–*.wt | 主表恢复 | 正在恢复核心业务集合,尤其是大表(~4.3GB each) |
| (未见) | preparing data, recovering oplog, done | 待完成 | 预计接下来会做 oplog 截断、standalone 模式启动、元信息清除 |
能看到还原了完整备份,proders和products表都在。

进行增量备份的恢复,每次还原之前需要确认pbm list可以看到备份列表信息。
#进行恢复第二次着增量备份测试
./pbm restore 2026-01-01T08:58:49Z
pbm-agent.log 日志如下
使用阿里云千问模型分析日志,梳理流程图和关键环节
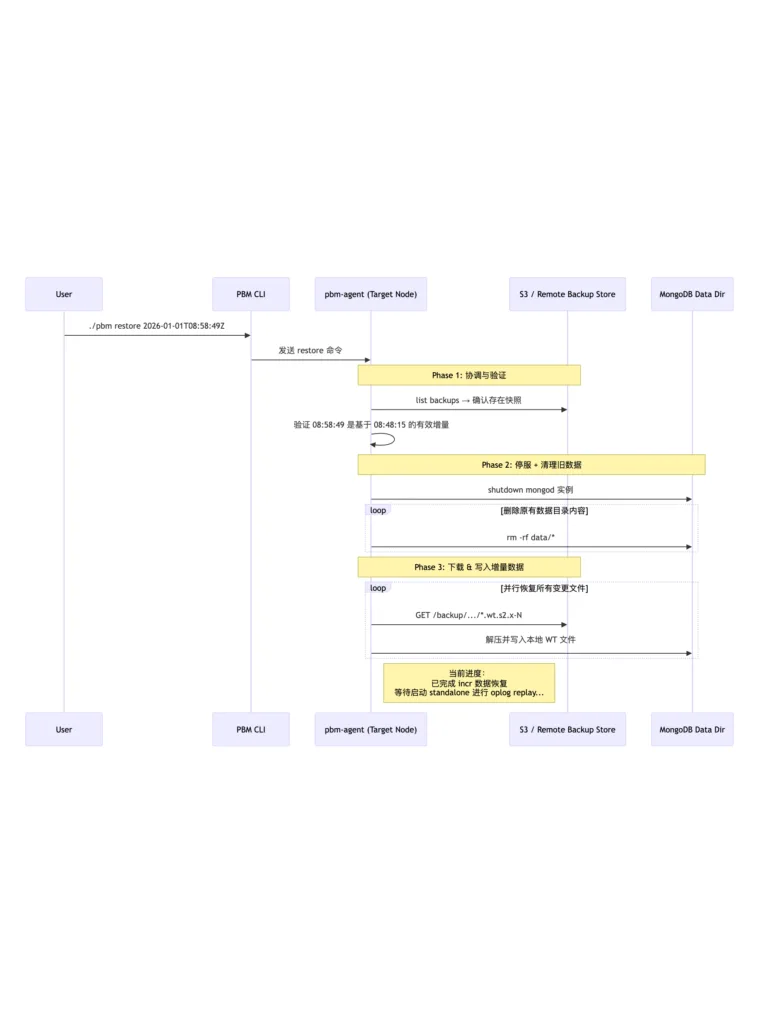
关键环节详细拆解(按时间线)
| 时间戳 | 日志片段 | 阶段 | 功能说明 |
| 17:15:17 | starting PITR routine | 启动监听 | Agent 正常运行中,准备接收命令 |
| 17:15:40 | got command resync | 状态同步 | 获取当前备份列表和恢复任务 |
| 17:15:41 | bcp: 2026-01-01T08:48:15Z, 08:58:49Z | 备份发现 | 成功识别两条增量快照,构成一条链 |
| 17:16:49 | got command restore […] snapshot: 2026-01-01T08:58:49Z | 接收指令 | 用户发起恢复请求,指定第二个 incr 包 |
| 17:16:50 → 17:17:20 | moving to state starting → running | 状态广播 | 创建 .starting, .running 标志文件,协调集群行为 |
| 17:17:20 | stopping mongod and flushing old data | 停止服务 | 安全关闭目标实例 |
| 17:17:21 → 17:17:23 | remove /disk0/mongodb_test/… | 清理环境 | 删除原 data 目录下所有文件(为写入新状态做准备) |
| 17:17:22 → 17:17:32 | copy <…> 开始 | 数据恢复 | 从远程存储拉取 08:48:15Z 中记录的所有 .wt 文件、journal、元文件 |
| 17:17:32 | [pitr] stopping main loop | 主循环停止 | 表示本次 agent 主流程结束(可能是退出或待下一步处理) |
还原完成后启动数据库,可以看到orders表不见了

留意点
需要注意MongoDB的版本和PBM版本的对应关系(PBM和MongoDB版本对应关系),版本特别低的MongoDB不支持增量备份。
MongoDB副本集群的升级可以参考下面的流程:
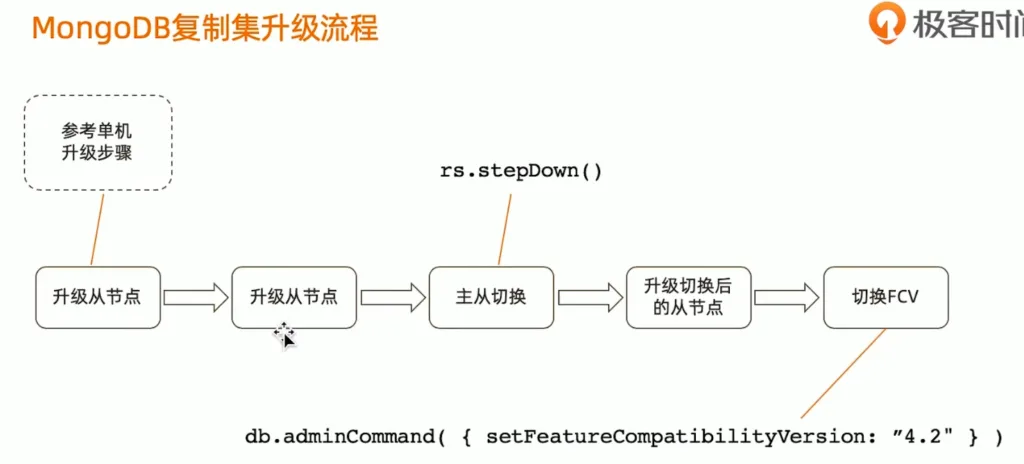
MongoDB副本集群程序升级后,新版本的二进制文件虽然已经运行,但为了保证兼容性和可回滚性,MongoDB 默认不会立即启用所有 4.4 的新特性。
这个“开关”就是通过 featureCompatibilityVersion(简称 fCV)来控制的。
MongoDB集群升级到7.0开启新版本特性支持,有一个提示:
MongoServerError[Location7369100]: Once you have upgraded to 7.0, you will not be able to downgrade FCV and binary version without support assistance. Please re-run this command with 'confirm: true' to acknowledge this and continue with the FCV upgrade.这里是MongoDB 7.0 引入了一个不可逆升级警告(point of no return):
⚠️ 一旦将 featureCompatibilityVersion 设置为 “7.0”,你就不能再降级回 6.0 或更早版本了!
即使你想回滚二进制文件或配置,也必须联系 MongoDB 官方技术支持才能完成降级 —— 否则会面临数据损坏风险。
写在最后
percona PBM 可以解决数据量在1T并且OPlog时间在3-7天的这种副本集群的增量备份需求,如果集群数据屋里存储达到2T以及以上并且Oplog时间较短,全量备份写入s3或者其他存储的时间很大概率会超过Oplog的时间,导致后面增量备份没有办法实现。
数据量很大最好的办法还是拆库拆表,升级为分片集群。但是分片集群的备份又带来很大的不确定性,各大云厂商还支持磁盘快照方式的备份,在MongoDB备份上还是基于实际情况进行规划最好。
受限于遇到和网上搜到的MongoDB信息整理完成,作为2026年技术分享第一篇。
祝大家新年马到成功!